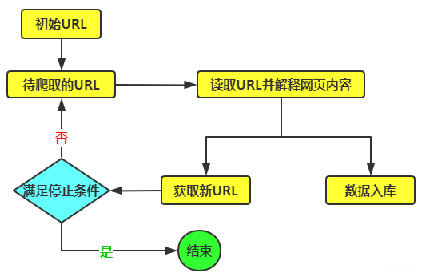
今天我要和大家聊一聊一个让程序员们头疼不已的话题——高并发海量数据爬取。在这个信息爆炸的时代,我们需要从互联网上抓取大量的数据,便于进行分析、挖掘和应用。但是面对庞大的数据量和复杂的网络环境,我们应该选择哪种编程语言来完成这项任务呢?让我们一起来探讨一下吧! 首先,我们让来Python看看这个高效的编程语言。Python简洁、高效的语法和丰富的第三方库而闻名于世。对于爬虫任务来说,Python的强大的生态系统提供了许多方便的工具和库,例如BeautifulSoup和Scrapy,使得数据爬取变得轻而易举。此外,Python还具有良好的吸引力和易于维护的特点,对于这种长期运行的爬虫任务来说非常重要。 然而,当我们面对高运算量和海量数据时,Python 的性能可能会成为一个瓶颈。尽管 Python 的解释器近年来有了很大的改进,但它仍然无法与一些编译型语言相媲美。处理大规模数据时,Python的速度可能会变得相对较慢,这可能会导致爬虫任务的执行时间过长。 这时我们来看看Java这个老牌编程语言。Java中的并发性能观察和稳定性而闻名。Java的线程模型和内存管理机制使其能够处理高并发任务时的表现。此外,Java的广泛优秀应用和成熟的生态系统也为爬虫任务提供了丰富的选择。 例如:让我们通过一个简单的例子来比较Python和Java在高并发海量数据爬取方面的表现。假设我们需要从一个网站上抽取10000个页面的数据,并且每个页面的抽取都需要使用代理服务器。下面是Python和Java两种语言的代码示例: python示例:
#亿牛云爬虫代理参数设置
proxyHost = 't.16yun.cn'
proxyPort = 30001
def crawl_page(url):
proxies = {
'http': f'http://{proxyHost}:{proxyPort}',
'https': f'http://{proxyHost}:{proxyPort}'
}
response = requests.get(url, proxies=proxies)
# 处理页面数据的逻辑
...
# 并发抓取10000个页面
urls = ['http://example.com/page{}'.format(i) for i in range(10000)]
for url in urls:
crawl_page(url)
Java示例:
import java.net.InetSocketAddress;
import java.net.Proxy;
import java.net.URL;
import java.net.URLConnection;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class Crawler {
private static final String PROXY_HOST = "t.16yun.cn";
private static final int PROXY_PORT = 30001;
public static void crawlPage(String url) throws IOException {
Proxy proxy = new Proxy(Proxy.Type.HTTP, new InetSocketAddress(PROXY_HOST, PROXY_PORT));
URLConnection connection = new URL(url).openConnection(proxy);
// 处理页面数据的逻辑
...
}
public static void main(String[] args) throws IOException {
ExecutorService executor = Executors.newFixedThreadPool(10);
// 并发抓取10000个页面
for (int i = 0; i < 10000; i++) {
final int page = i;
executor.submit(() -> {
try {
crawlPage("http://example.com/page" + page);
} catch (IOException e) {
e.printStackTrace();
}
});
}
executor.shutdown();
}
}
通过上面的例子,我们可以看到Python和Java在高并发海量数据爬取方面的不同表现。Python实现简洁、优雅的语法和丰富的第三方库在编写爬虫任务时非常方便。然而,当在海量数据和高并发的情况下,Java的面对并发性能和稳定性更加出色。 因此,如果你的爬虫任务需要处理大规模数据和高并发情况,我建议你选择Java作为编程语言。当然,这并不意味着Python不适合爬虫任务,对于一些小规模的数据爬虫任务,Python 仍然是一个非常好的选择。