
在Kafka中一个分区日志其实就是一个备份日志,kafka利用多个相同备份日志来提高系统的可用性。这些备份日志其实就是所谓的副本。
Kafka的副本具有leader副本和follower副本之分,leader副本为客户端提供读写请求,follower副本只是用于被动地从leader副本中同步数据,对外不提供读写服务。
Kafka的所有节点所有副本假设都在正常运行,那么leader副本会一直不变,但是所谓世界上没有绝对稳定的系统,一旦kafa的leader副本节点出现了问题,那么follower副本需要竞争上岗成为leader副本,但是并不是所有的follower副本都有资格竞争上岗,很明显假设一个follower落后的数据远远少于leader副本,它是没有资格的。因此Kafka内部维护了一组具有资格的follower副本,他们统称ISR。
ISR中的副本会被剔除,也会有新增。
关键的概念点
下图主要讲述了Kafka日志中重要概念,下图的相关概念事关生产、消息消费、ISR以及副本同步机制。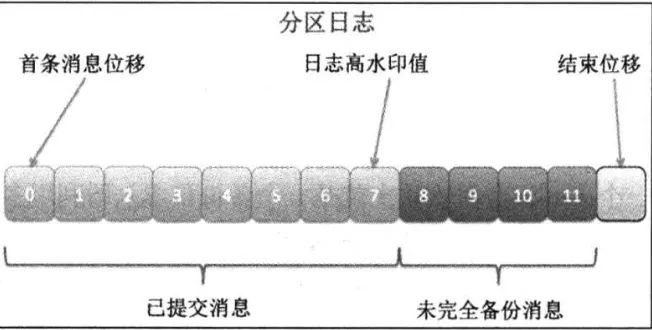
首条消息位移(offset):保存了该副本中所含的第一条消息的offset
日志高水印值(HW):leader副本的HW决定了消费者所能消费的消息范围,低于等于HW的消息均可被消费者消费
结束位移(LEO):LEO总是指向下一条消息写入的位置,处在leader的HW和LEO之间的消息表示还未完全备份。只有所有处于ISR中副本都更新了自己LEO以后,leader的HW才会右移表示写入消息成功。
ISR
ISR其实就是Kafka内部维护的具有竞争上岗的一组与leader同步follower的副本集合。
follower副本与leader副本不同步的原因:
同步数据请求速度追不上:follower副本在一段时间无法追上leader副本端的消息接收速度。比如follower副本的网络I/O阻塞,这会导致follower副本同步leader副本的速度大大降低
进程卡住:follower副本一段时间无法向leader发出请求,比如follower频繁的进行GC
新创建的副本:用户主动增加副本数,新创建的副本在启动后会追赶leader的进度,这段时间新增的follower副本通常与leader副本是不同步的
replica.lag.max.messages
该参数用来检测同步数据请求速度追不上的问题,如果ISR中的副本消息数落后于leader副本的消息数超过了该参数的设置,将会被踢出ISR。
这个参数在kafka0.9.0.9版本之后被移除,为什么被移除呢?
肯定是有他的弊端的。考虑以下这个情况,kafka在的生产者的生产速率不是平稳的,会有高峰会有低峰,在高峰的时候,由于消息大量聚集产生,导致ISR中的消息与Leader的消息差超过了该数值,因此ISR中的副本将会被踢出。
但随着生产消息速率的稳定和下降,并且此时follower副本也在全力追赶leader副本,当follower副本重新追上leader副本时,又会重新加入ISR。
replica.lag.max.ms
该参数用来检测另两种情况:如果在该时间内,follower副本无法向leader副本请求数据,那么将会被踢出ISR。
由于在新的版本中移除了replica.lag.max.messages参数的设置,因此replica.lag.max.ms也用于同步数据请求速度追不上问题的检测,但用在次问题的检测上时,检测机制是只要follower副本落后于leader的时间不持续性超过该参数即视为同步,如果持续性超过该参数即视为不同步。
本文分享自微信公众号 - shysh95(shysh95)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。






