
点击上方蓝字关注我们

本文将详细介绍 Hive 使用 hql 语句对 WordCount 的实现

一、环境准备
我这里搭建的是高可用的完全分布式集群,至于如何搭建我就不多说了,有时间我整理下各个框架的分布式集群搭建文档送给大家。
1.启动 Zookeeper 集群:zkServer.sh start
2.启动HDFS集群:start-dfs.sh
如果 NameNode 没有启动,需要手动启动:hadoop-daemon.sh start namenode
3.启动 Yarn 集群:start-yarn.sh (启动nodemanager)、yarn-daemon.sh start resourcemanager(手动启动 resourcemanager)
4.查看启动情况:jps
图5-4 jps进程查看
5.启动Hive集群
(1)node1 启动mysql:service mysqld start
(2)node3(hive服务端)启动元数据服务
ss -nal 看一下目前的端口号使用情况
hive --service metastore 启动元数据服务
(3)这个时候再开一个shell窗口:ss -nal看一下有没有9083的端口
有的话在客户端输入hive回车就可以启动hive终端了
数据文件上传至 HDFS
words.txt
[root@node4 ~]# vim words.txt
hadoop hive mapreducehive hbasehbase hive mapreduce hadoophive hadoop hello
上传至HDFS
[root@node4 ~]# hdfs dfs -put words.txt /demo_data/[root@node4 ~]# hdfs dfs -ls /demo_dataFound 1 items-rw-r--r-- 2 root supergroup 79 2020-07-14 10:04 /demo_data/words.txt
Hive表设计
words表
这里建外部表比较合适,hql 语句很简单,如下
create external table words(line string)location '/demo_data/'
执行
hive> create external table words > ( > line string > ) > location '/demo_data/';OKTime taken: 0.173 secondshive> select * from words;OKhadoop hive mapreducehive hbasehbase hive mapreduce hadoophive hadoop helloTime taken: 0.096 seconds, Fetched: 4 row(s)
words_result表
一会儿hive处理的结果存放在一个内部表里比较合适
先把它建出来,语句如下
create table words_result(word string,ct int);
hive> create table words_result > ( > word string, > ct int > );OKTime taken: 0.189 seconds
实现WordCount
1.以空格为单位切割单词
hive> select split(line,' ') from words;OK["hadoop","hive","mapreduce"]["hive","hbase"]["hbase","hive","mapreduce","hadoop"]["hive","hadoop","hello"]Time taken: 0.123 seconds, Fetched: 4 row(s)
2.用内置表生成函数(UDTF)里的explode函数把上面结果变为一列
hive> select explode(split(line,' ')) from words;OKhadoophivemapreducehivehbasehbasehivemapreducehadoophivehadoophelloTime taken: 0.111 seconds, Fetched: 12 row(s)
3.完整的 hql 语句
from (select explode(split(line,' ')) word from words) tinsert into words_resultselect word,count(word)group by word;
注意:不管是SQL还是hql,count()括号里面最好不要用星号,建议使用字段或者随便一个数字,因为星号会增加查询负重
执行
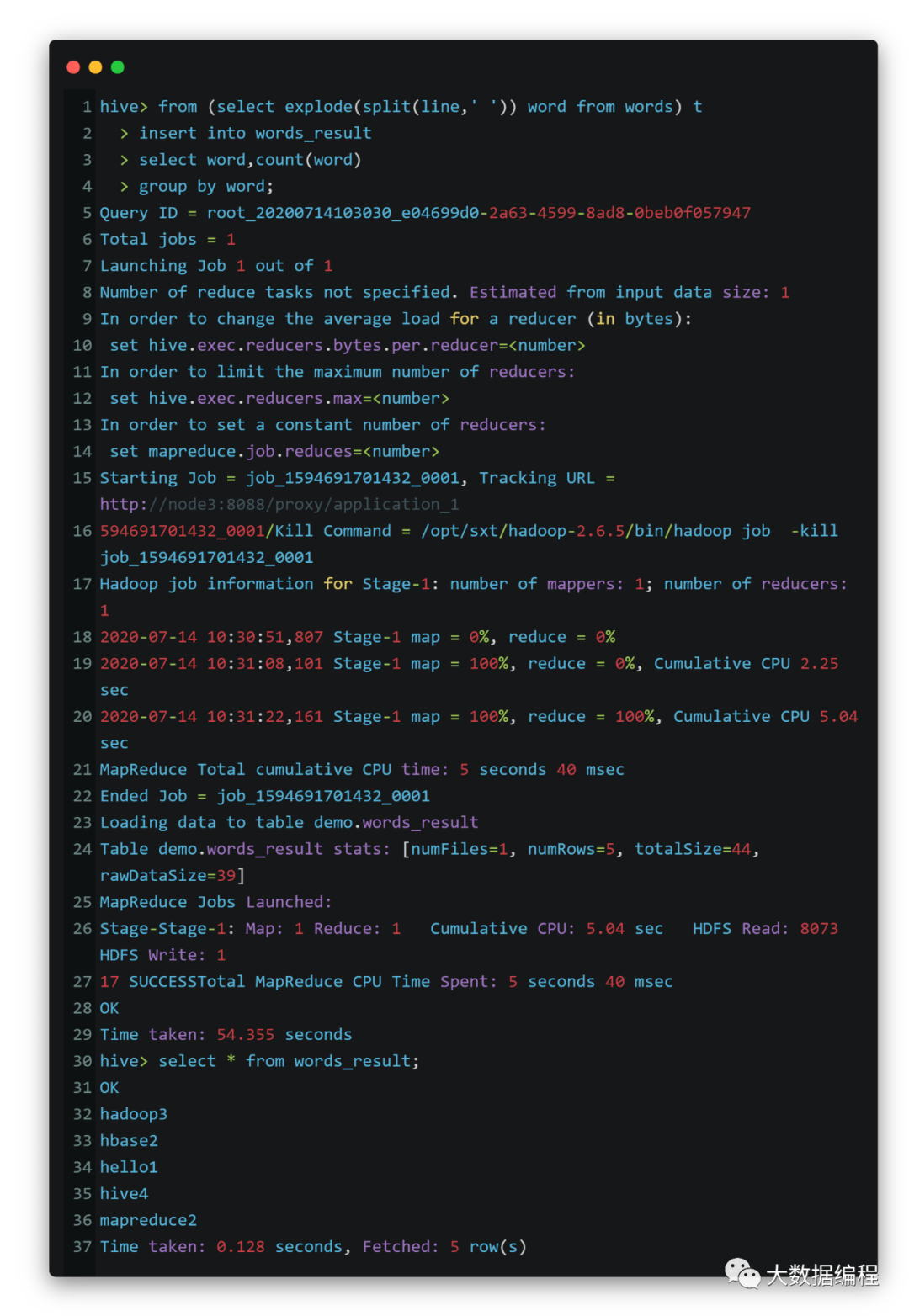
结果达到预期,Over!


长按二维码关注我们

大数据编程
微信号 : bigdataBC
专注技术分享!
“ 在看”的永远18岁~

本文分享自微信公众号 - 大数据编程(bigdataBC)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。









