简介:基于报告,ARMS 能快速的整合上下文,包括 Prometheus 监控进行监控。还有前端监控的相关数据,都会整合到报告里面,进行全方位检测来收敛相关问题。
作者:延福
在开始正式内容前,我想跟大家聊一聊为什么要做告警平台。
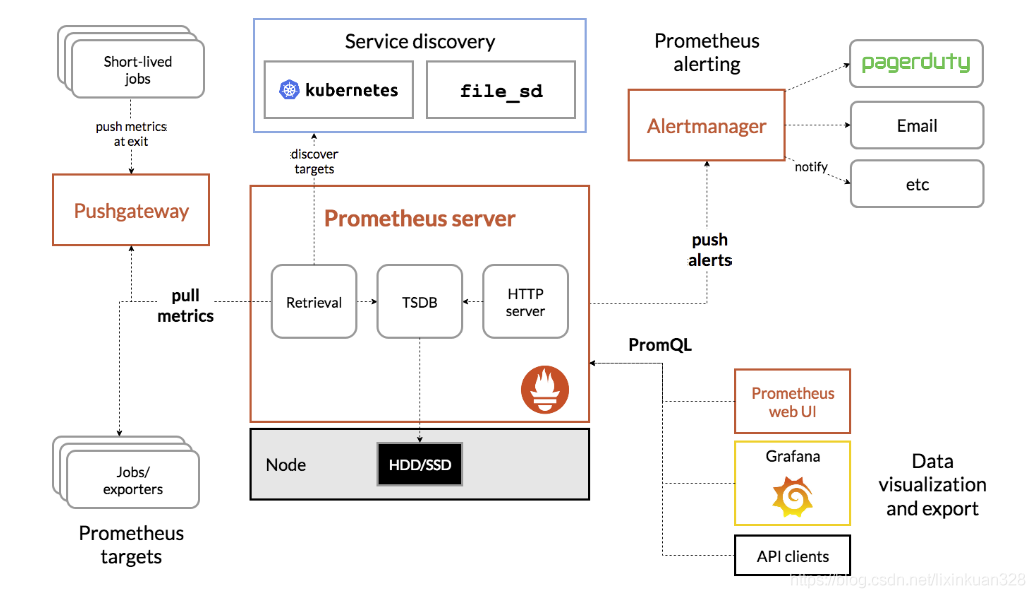
随着越来越多企业上云,会用到各种监控系统。这其中,用 Skywalking 做 tracing,Prometheus 做 matches,ES 或者云上日志服务,做日志相关监控,随便算算就至少有三套系统了,这其中还不包括云监控等云平台自身的监控平台。这么多监控平台如果没有统一配置告警的地方,就需要在每个系统中都维护一套联系人,这会是一个复杂的管理问题。与此同时,会非常难以形成上下文关联。比如,某一个接口出现问题,那可能云监控的拨测在报警,日志服务的日志也在报警,甚至 ARMS 应用监控也在报警。这些报警之间毫无关联,这是在云上做告警云很大的痛点。
其次无效告警非常多。什么叫无效告警?当业务系统出现严重故障时,关联系统也可能出现相关告警。而且关联告警会非常多,进而将关键信息淹没在告警海洋中,导致运维人员没办法及时对告警进行处理。最后,现在很多报警经常发生,但是没有人处理,就算有人处理了,但处理情况怎么样,关键性告警从发生到修复的时间到底有多长,每天有多少人在处理,企业的 MTTR 能不能算出来?这也是我们要做统一告警平台要解决的问题。

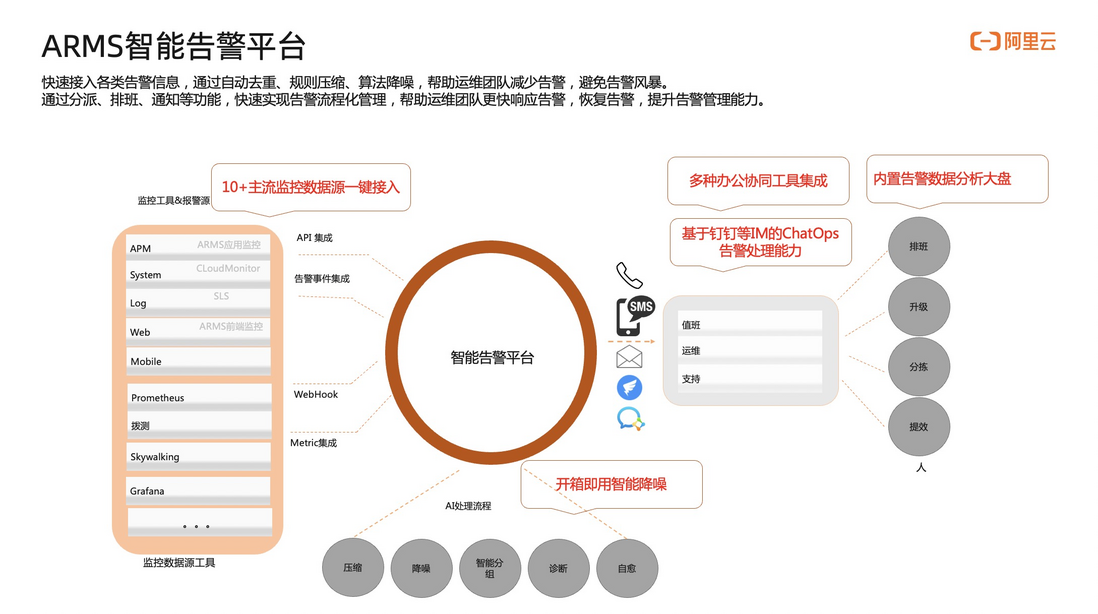
为了解决以上三个问题,ARMS 的智能告警平台应用而生。
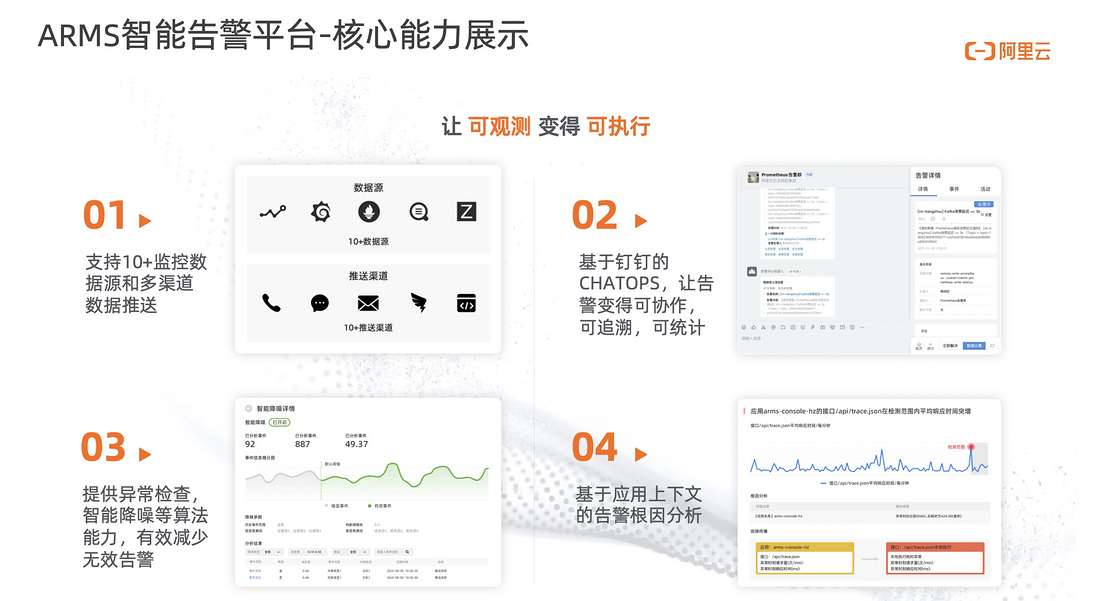
首先,集成了众多监控系统包括 ARMS 本身的应用监控、云监控、日志服务等十几家监控系统,并提供开箱即用的智能降噪能力。同时,为了更高效的协作,整个协同的工作流都可以放在钉钉、企业微信等 IM 工具上,用户可以更加便捷的去处理和运维相关的告警。最后,提供告警分析大盘帮助用户来分析告警是不是每天都有人在处理,处理情况是什么样的。
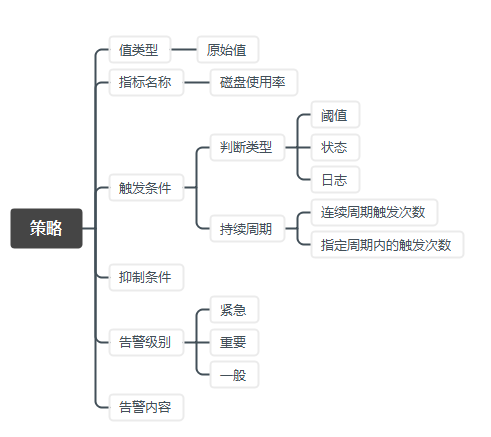
告警要在脑海里形成抽象的概念,到底分成哪些步骤?
第一、从事件源产生告警事件,事件是告警发送之前的状态。事件并不会直接发送进来,它需要和告警的联系人匹配完成以后,才能生成告警流程。这张图简单的介绍了告警的过程。这也是很多同学用系统时候会经常出现的问题:配置了事件,却不知道怎么样产生告警。必须要事件加联系人才能产生告警。
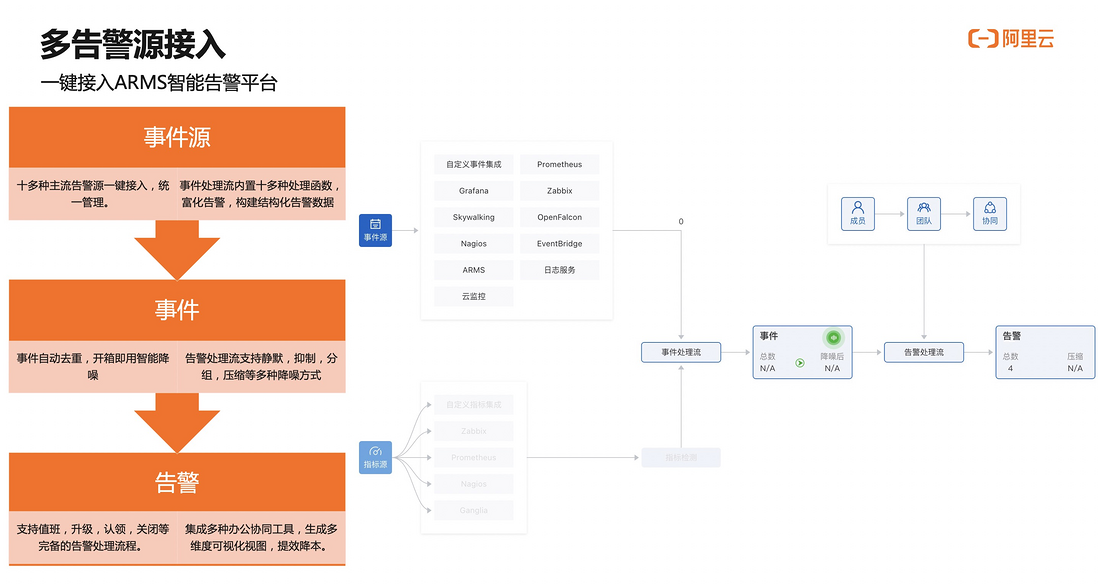
第二、很多同学用的告警系统默认没有接入。我们也提供了灵活告警事件源的接入方式。可以按照自定义的接入方式,将事件传进来,我们来清洗字段,最后接入形成告警平台可以理解的告警。
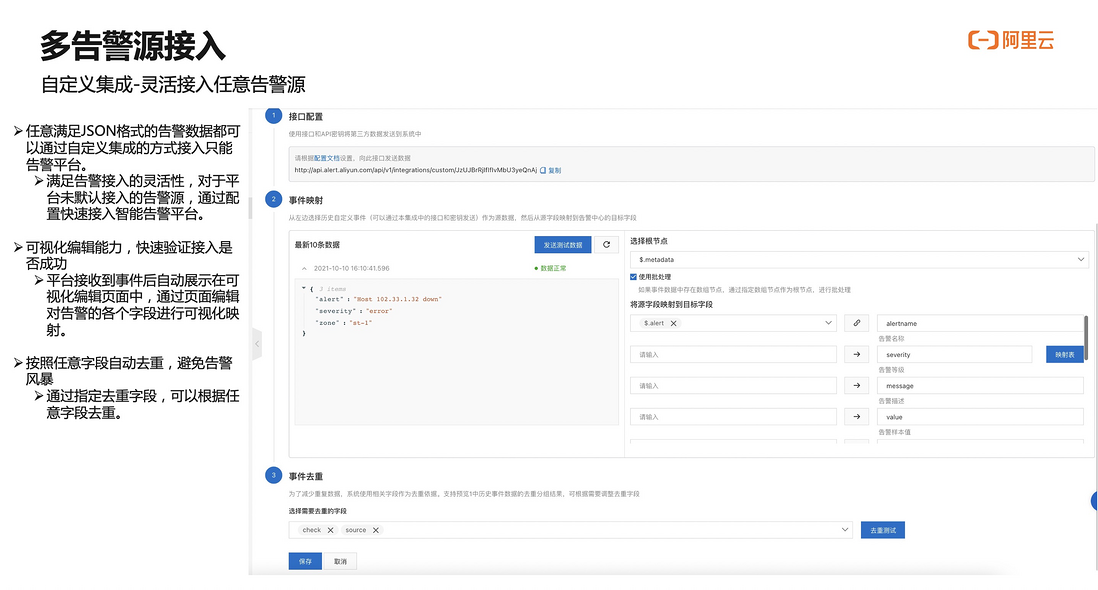
工单系统举例,希望系统里产生很重要的事件也往告警平台去传时,可以把工单系统的报警事件通过 webhook 的方式发送到告警平台。识别并设置相关内容,再通过电话或短信方式通知到相应联系人。告警平台本质上是接受事件,把告警团队相关信息配到告警平台,帮用户把事件给这些团队的联系人进行匹配发送。

接下来,展示一下这部分能力是怎么实现的,在界面上是什么样的功能。
首先,打开 ARMS 控制台,拉到最下面告警管理模块。我们可以看到概览,其中包括大部分接入过程、事件处理流程等等。
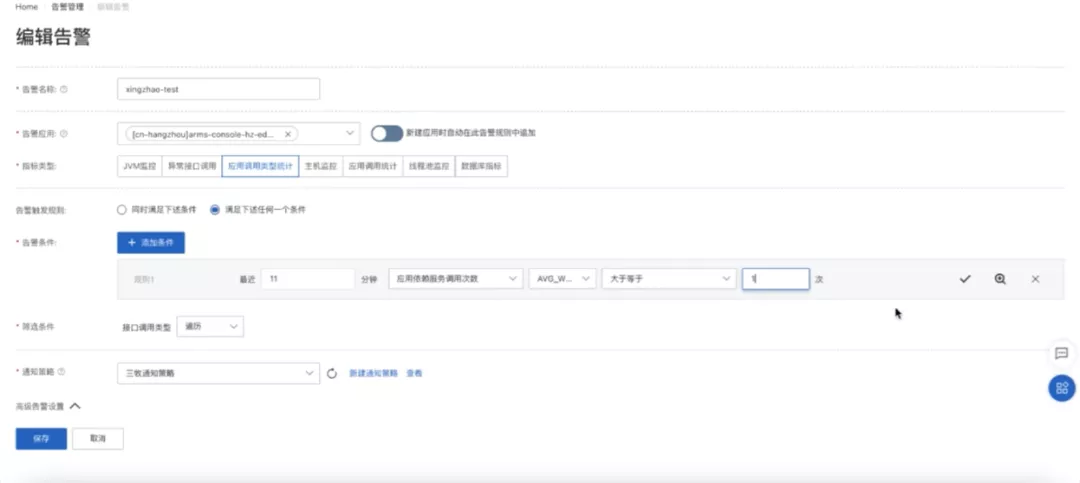
现在已经用 ARMS 应用监控的用户,可以直接在其中先创建一个告警的规则。条件是应用响应时间,调用次数大于一次的时候,它就会产生一个事件。
如果是开源 Skywalking 或其他服务,需要到其中去把告警规则设好,把相应的事件传递过来。传递进来以后,在报警事件列表里面就能看到对应报警的事件了。
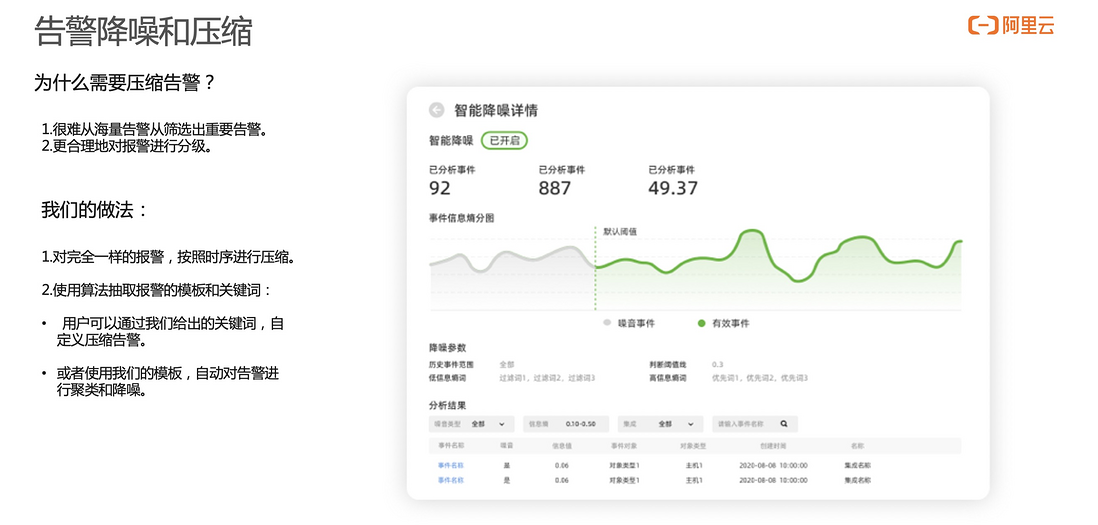
报警事件发送进来以后。首先会对告警事件进行降噪处理,识别告警目前最多关键词是什么样,哪些关键词高度重复,或者哪些内容是高度匹配的。同时,根据我们给出的关键词进行压缩。比如,不希望能收到来自于测试环境的告警,可以把“测试”这两个字作为屏蔽词,这样带“测试”相关屏蔽词的功能,告警事件就不会进行二次报警。
告警事件传递过来后,整个数据都会放在事件大池子里面。需要对这些事件进行分配,这个事件到底谁去接收他,谁来对这些事件做通知和排班管理。按照告警名称或者其他的字段等在告警里面预制的字段去匹配,对 Pod 状态的异常做匹配,那它会生成告警。
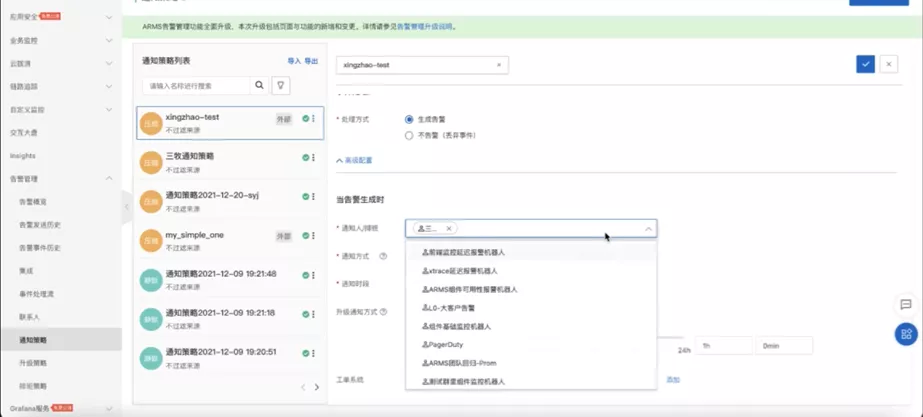
生成告警以后,可以在联系人里面去配置相关联系人,其中包括导入通讯录或配钉钉机器人等等。在通用策略里面,进一步配置,让用户配一个机器人或者真实的人去接受告警。也可以是对工单系统,比如 Jira 等平台里面去做对接,保证信息可以传递到他们那边。
配完通知策略以后,一旦产生告警,就可以收到相关的告警了。比较推荐您使用的是通过钉钉来接收相关的报警。
这里展示一下怎么样通过钉钉来接收相关的告警。比如,这是我们接收到钉钉相关告警。在接收到这个告警以后,对这条告警消息,只需有一个钉钉账号,不需要有理解这些相关信息,或者登录到系统,直接对这个告警进行认领。因为和钉钉系统深度集成,可以去认领告警,也可以在认领完以后点解决这条告警。
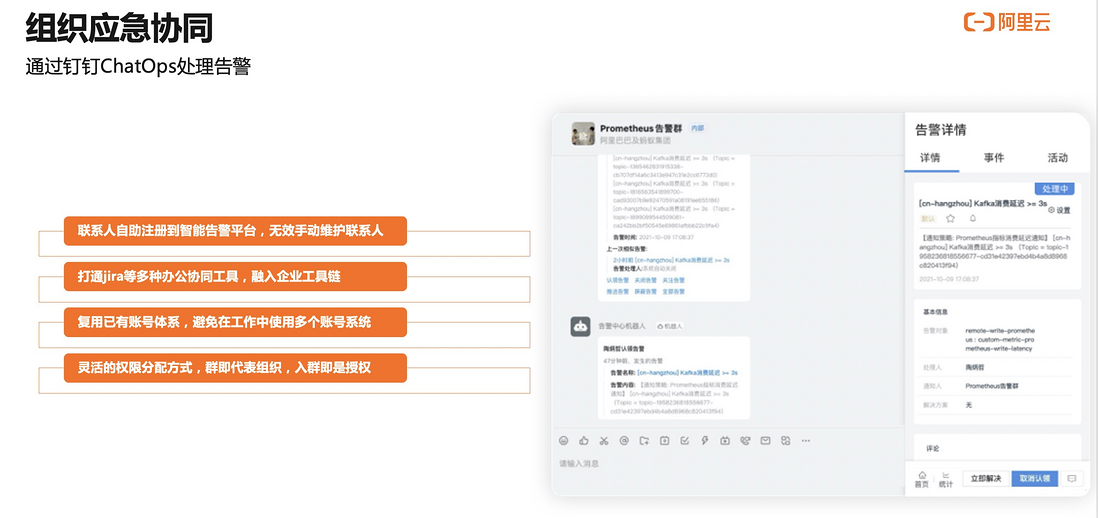
我们会把过程记录在活动里面。用户就会知道认领和关闭告警的整个过程。同时,每天会针对情况做统计,比如今天发生告警的数量,是否有处理,哪些没有处理,整体处理情况是怎么样的。如果团队比较大,有非常多运维同学,而且会有 L1 和 L2 分层运维同学的时候,可以使用排班功能进行线上排班。比如,这一周是某个同学接受告警,下一周是另外的同学。同时,也可以做升级策略的排班管理。重要告警在十分钟内没有人去做认领时,对重要告警做相应升级。
作为运维主管或运维总监,需要了解每天发生的这么多告警,经过一段时间后,它是不是有收敛或平均 MTTR 用了这些工具以后,有没有提升。我们提供了告警大盘,通过这个告警大盘可以了解到每天告警平均响应时间以及大家处理情况。MTTx 相关时间等统计数据会在这个大盘里面给用户进行展示,同时这个大盘是集成在 Grafana 上面,可根据实际需求,把相关数据放 Grafana 上,或者您的 Prometheus 数据源里面做二次的开发。
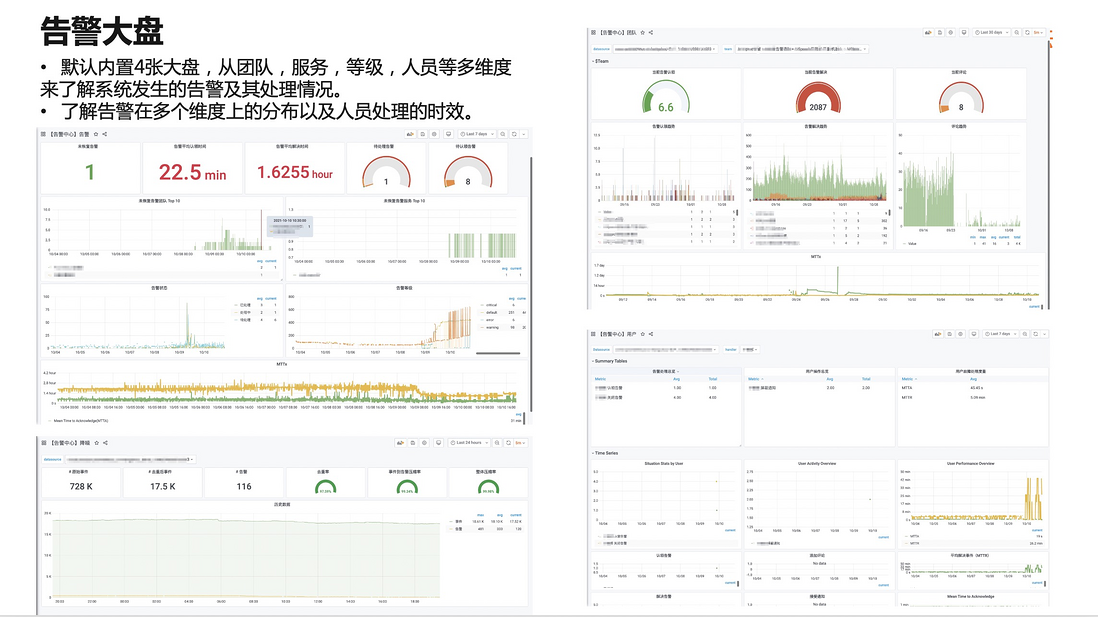
告警不仅是管理和收集的过程。很多时候虽然发现了告警。在告警处理过程中,阿里云是否可以提供一些建议参考。对此,我们也提供了相应功能来增强这一块的能力。
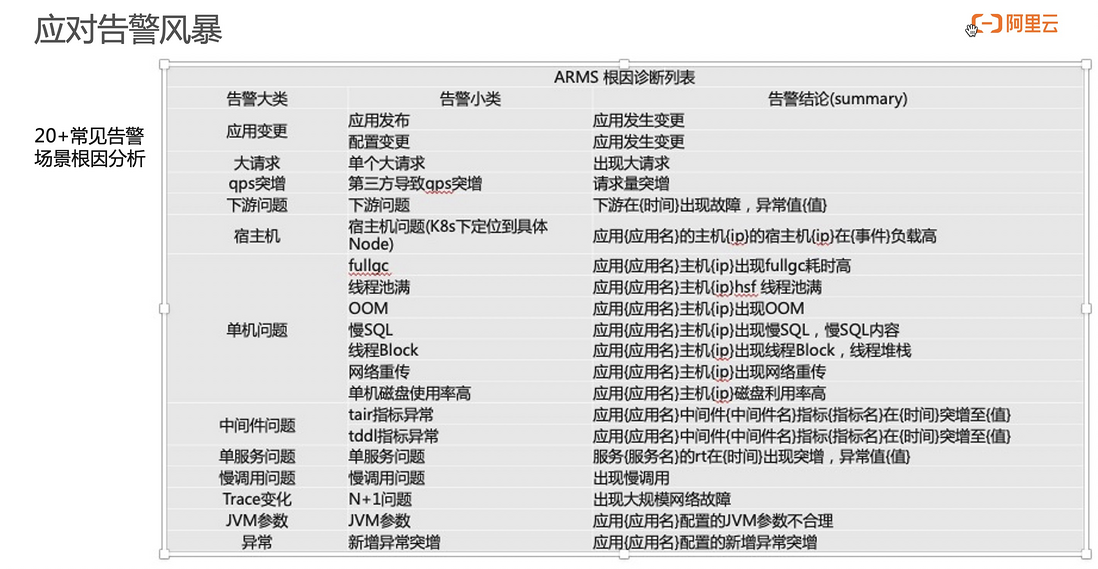
首先,基于类似应用监控的产品,提供一系列默认报警能力。一旦产生相关报警,我们会提供相关诊断能力。在如上图 20 多种场景下,会提供自动诊断报告。
举一个例子,应用的响应时间做突增,我们会生成一个直观的报表。在这个报表中,会告诉你当前突增的原因是什么。然后会整体的检测这个应用突增以后到底是哪些因素导致的。一般来说,这个诊断逻辑和普通的诊断逻辑是一样的。应用突增会去先检测一下多个主机是不是有突增,然后是不是接口有突增。这些接口如果它响应时间的数据特征是和整个应用一致,会在进一步分析这个接口里面到底又是哪些方法有突增,他传递的入参是什么,为什么有这样的突增?同时我们也会给出来一些特征请求告诉用户,慢的请求是怎样运行的。
以这个 version.json 接口为例,它是在对应的这个时刻,与应用有类似的突增。主要的核心方法就是这样一个方法,导致了接口缓慢。
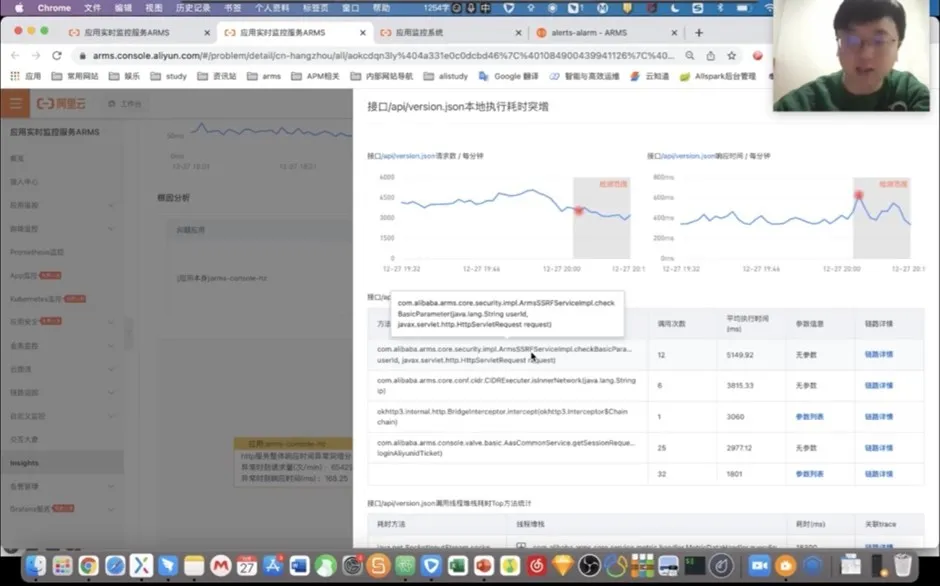
同时我们结合当时打出来的堆栈可以再次确认,当时就是个 handler 方法导致了它的缓慢,那接下来我们就可以结合代码进一下进一步的优化了。
这就是 ARMS insight 针对常见问题深入分析的一个 case。基于报告,ARMS 能快速的整合上下文,包括 Prometheus 监控进行监控。还有前端监控的相关数据,都会整合到报告里面,进行全方位检测来收敛相关问题。
原文链接
本文为阿里云原创内容,未经允许不得转载。