
点击蓝字 关注我们
GitHub:https://github.com/Oneflow-Inc/oneflow

(点击“阅读原文”,即刻进入 GitHub 仓库!)
前言
本文主要内容是如何用 OneFlow 去复现强化学习玩 Flappy Bird 小游戏这篇论文的算法关键部分,还有记录复现过程中一些踩过的坑。
希望读者能通过这篇文章可以了解到 OneFlow 框架 Python 前端的一些特点。
相关论文地址:
http://cs231n.stanford.edu/reports/2016/pdfs/111_Report.pdf
OneFlow 实现代码:
https://github.com/Ldpe2G/DeepLearningForFun/tree/master/Oneflow-Python/DRL-FlappyBird
OneFlow GitHub 仓库:
https://github.com/Oneflow-Inc/oneflow
OneFlow 文档:
https://docs.oneflow.org/index.html
运行结果

论文简要解读
问题的定义
如果有玩过 Flappy Bird 这个游戏的读者会知道,对于玩家来说只有两个选项,点击或者不点击屏幕。
而每点击一下屏幕游戏中的 bird 就会向上跳一下,否则 bird 就会一直往下掉,当 bird 碰到底部或者柱子的时候游戏就结束了。
bird 每穿过一次两根柱子中间就能得一分,而这个游戏是没有终点的只要 bird 不碰到柱子和底部,玩家就可以一直玩下去。
论文提出的方法
对于网络模型来说,就是要学会根据当前输入的状态输出合适的动作。和分类问题是类似的,不过对于这个任务来说并没有标注信息。
论文里面则是采用了强化学习的思路来解这个这问题。
通过执行当前网络输出的动作,然后在游戏中得到的 reward 来评价该动作。
网络的输入状态由当前帧和前几帧(总共n帧,n在实验中设为4)拼接组成,这样子可以更好地给模型提供轨迹信息。
其实理想情况下下输入状态应该是从第一帧开始到当前帧,但是为了减少状态空间只用了有限的帧数。
网络结构定义
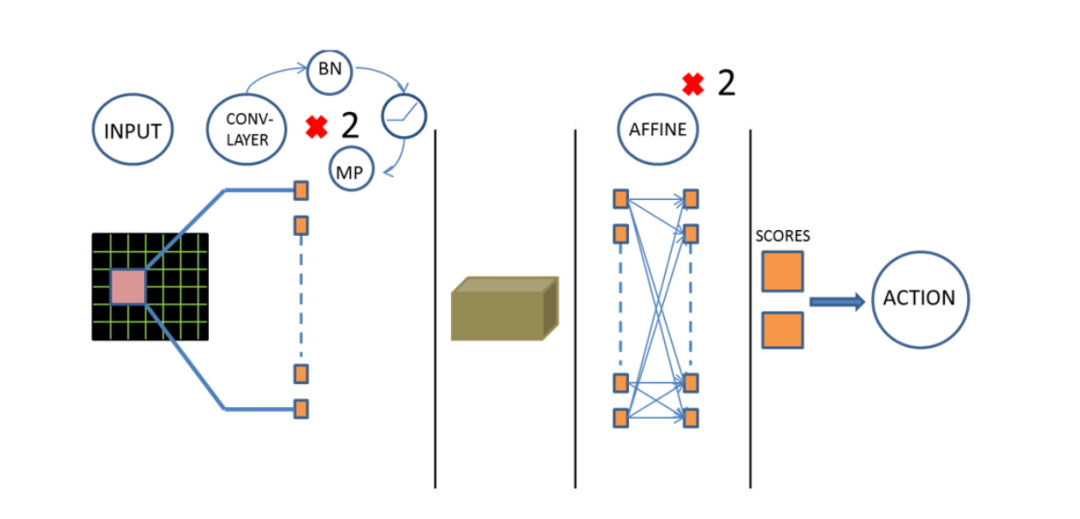
网络输入大小是 (batch, c, 64, 64),c 在实验中取 4 也就是把相邻 4 帧的灰度图(具体实现上还做了二值化)拼接在一起。
网络结构主要包括两层卷积和两层全连接,每层卷积(out_channel=32, kernel=3x3, stride=1, pad=1)之后都会按顺序接 batchnorm、 relu 激活和 max pooling(kernel=2x2, stride=2)。
最后一层pooling 输出大小为 (32, 32, 16, 16),然后经过 Flatten (具体实现是经过一个 reshape 来实现)之后接全连接层,在第一层全连接(out_chanel=512)之后会有一层 bn 和 relu,最后一层全连接的输出就是2维,表示对两个动作(点击或不点击屏幕)的预测。
这里网络最后输出两维向量,这个向量的索引表示对应的动作,而索引对应的位置的值就是Q值。
OneFlow 实现细节
网络结构定义
在 OneFlow 中定义一个网络结构和 TensorFlow 是类似的,下面是定义论文中网络结构的代码:
https://github.com/Ldpe2G/DeepLearningForFun/blob/master/Oneflow-Python/DRL-FlappyBird/BrainDQNOneFlow.py#L114
# 输入 input_image的类型是 flow.typing.Numpy.Placeholder,# 这个只是数据占位符,用于构建计算图,并没有真实数据。# 而通过指定的返回值类型为 flow.typing.Numpy,可以告之 OneFlow 此函数调用时,# 返回的真实数据类型为 numpy 对象def createOfQNet(input_image: tp.Numpy.Placeholder((BATCH_SIZE, 4, 64, 64), dtype = flow.float32), var_name_prefix: str = "QNet", is_train: bool = True) -> tp.Numpy: # 获取网络参数,具体 getQNetParams 函数的定义见下文 conv1_weight, conv1_bias, conv2_weight, conv2_bias, fc1_weight, fc1_bias, fc2_weight, fc2_bias = \ getQNetParams(var_name_prefix = var_name_prefix, is_train = is_train) # 定义网络结构 conv1 = flow.nn.compat_conv2d( input_image, conv1_weight, strides = [1, 1], padding = "same", data_format = "NCHW" ) conv1 = flow.nn.bias_add(conv1, conv1_bias, "NCHW") conv1 = flow.layers.batch_normalization(inputs = conv1, axis = 1, name = "conv1_bn") conv1 = flow.nn.relu(conv1) pool1 = flow.nn.max_pool2d(conv1, 2, 2, "VALID", "NCHW", name = "pool1") conv2 = flow.nn.compat_conv2d( pool1, conv2_weight, strides = [1, 1], padding = "same", data_format = "NCHW" ) conv2 = flow.nn.bias_add(conv2, conv2_bias, "NCHW") conv2 = flow.layers.batch_normalization(inputs = conv2, axis = 1, name = "conv2_bn") conv2 = flow.nn.relu(conv2) pool2 = flow.nn.max_pool2d(conv2, 2, 2, "VALID", "NCHW", name = "pool2") # pool2.shape = (32, 32, 16, 16), after reshape become (32, 32 * 16 * 16) pool2_flatten = flow.reshape(pool2, (BATCH_SIZE, -1)) fc1 = flow.matmul(a = pool2_flatten, b = fc1_weight, transpose_b = True) fc1 = flow.nn.bias_add(fc1, fc1_bias) fc1 = flow.layers.batch_normalization(inputs = fc1, axis = 1, name = "fc1_bn") fc1 = flow.nn.relu(fc1) fc2 = flow.matmul(a = fc1, b = fc2_weight, transpose_b = True) fc2 = flow.nn.bias_add(fc2, fc2_bias) return fc2
获取卷积层和全连接层的参数:
https://github.com/Ldpe2G/DeepLearningForFun/blob/master/Oneflow-Python/DRL-FlappyBird/BrainDQNOneFlow.py#L42
def getQNetParams(var_name_prefix: str = "QNet", is_train: bool = True): # 参数层初始化方法 weight_init = flow.variance_scaling_initializer(scale = 1.0, mode = "fan_in", distribution = "truncated_normal", data_format = "NCHW") bias_init = flow.constant_initializer(value = 0.) conv_prefix = "_conv1" conv1_weight = flow.get_variable( var_name_prefix + conv_prefix + "_weight", shape = (32, 4, 3, 3), dtype = flow.float32, initializer = weight_init, trainable = is_train ) conv1_bias = flow.get_variable( var_name_prefix + conv_prefix + "_bias", shape = (32,), dtype = flow.float32, initializer = bias_init, trainable = is_train ) # 中间省略部分代码 fc_prefix = "_fc2" fc2_weight = flow.get_variable( var_name_prefix + fc_prefix + "_weight", shape = (ACTIONS_NUM, 512), dtype = flow.float32, initializer = weight_init, trainable = is_train ) fc2_bias = flow.get_variable( var_name_prefix + fc_prefix + "_bias", shape = (ACTIONS_NUM,), dtype = flow.float32, initializer = bias_init, trainable = is_train ) return conv1_weight, conv1_bias, conv2_weight, conv2_bias, fc1_weight, fc1_bias, fc2_weight, fc2_bias
同名的参数是共享的,如果两个网络的卷积层都用了一个参数,那么这两个网络就共享了这个参数。
定义作业函数
上文定义网络之后,还不能运行前后向和参数更新,还需要定义一个作业函数,这个可以算是 OneFlow 的特色之处。
作业函数定义好之后,就可以像普通函数一样调用一次,然后就完成了网络的前后向和参数更新。
def get_train_config(): func_config = flow.FunctionConfig() func_config.default_data_type(flow.float32) func_config.default_logical_view(flow.scope.consistent_view()) return func_config# Oneflow 中的作业函数都要由 `oneflow.global_function` 修饰。# `oneflow.global_function` 函数第一个参数 type 指定了作业的类型 ,# type = "train" 为训练;type="predict" 为验证或推理。# function_config 默认为None。@flow.global_function("train", get_train_config())def trainQNet(input_image: tp.Numpy.Placeholder((BATCH_SIZE, 4, 64, 64), dtype = flow.float32), y_input: tp.Numpy.Placeholder((BATCH_SIZE,), dtype = flow.float32), action_input: tp.Numpy.Placeholder((BATCH_SIZE, 2), dtype = flow.float32)): # 可以通过 with flow.scope.placement 语句,告诉 oneflow 以下的 op # 是运行在哪些设备之上,比如让训练网络运行在GPU上 DEVICE_TAG = "gpu", # 后面的 0:0-n 表示0号机器,使用 0-n 号卡。 with flow.scope.placement(DEVICE_TAG, "0:0-%d" % (DEVICE_NUM - 1)): out = createOfQNet(input_image, var_name_prefix = "QNet", is_train = True) Q_Action = flow.math.reduce_sum(out * action_input, axis = 1) cost = flow.math.reduce_mean(flow.math.square(y_input - Q_Action)) learning_rate = 0.0002 beta1 = 0.9 # 目前 OneFlow 支持6种优化算法,分别是: # SGD、Adam、AdamW、LazyAdam、LARS、RMSProp flow.optimizer.Adam(flow.optimizer.PiecewiseConstantScheduler([], [learning_rate]), beta1 = beta1).minimize(cost)
更多关于作业函数的设置可以参考文档:
https://docs.oneflow.org/basics_topics/optimizer_in_function_config.html
第一次运行作业函数的时候会对图作构建和编译优化,之后就可以很高效的运行网络,
需要注意一点是,目前在一个作业函数运行起来之后,就不能再定义新的作业函数了,所以需要提前定义好所有的作业函数。
然后运行作业函数的时候,直接输入 numpy 数据,获取 numpy 输出:
https://github.com/Ldpe2G/DeepLearningForFun/blob/master/Oneflow-Python/DRL-FlappyBird/BrainDQNOneFlow.py#L234
# 训练过程简化代码示例def trainQNetwork(self): # 从 replayMemory 里面随机采样一个 batch minibatch = random.sample(self.replayMemory, BATCH_SIZE) # state_batch.shape = (BATCH_SIZE, 4, 80, 80) state_batch = np.squeeze([data[0] for data in minibatch]) action_batch = np.squeeze([data[1] for data in minibatch]) reward_batch = np.squeeze([data[2] for data in minibatch]) next_state_batch = np.squeeze([data[3] for data in minibatch]) # 运行预测作业,获取未来状态的Q值 Qvalue_batch = self.predictQNet(next_state_batch) terminal = np.squeeze([data[4] for data in minibatch]) y_batch = reward_batch.astype(np.float32) terminal_false = terminal == False # 对应论文公式(1) if (terminal_false).shape[0] > 0: y_batch[terminal_false] += (GAMMA * np.max(Qvalue_batch, axis=1))[terminal_false] # 运行训练作业,更新参数 self.trainQNet(state_batch, y_batch, action_batch)
模型参数的保存
OneFlow 中在作业函数定义之后,调用 ChenkPoit 的 init 函数就可以对参数做初始化,初始化的方式在定义参数 variable 的时候已经指定了详见上文。
还可以 调用 load 函数加载之前训练好的模型参数,而如果在加载某个参数模型的时候,提供的目录中不存在对应的参数,那么就会调用对应的初始化方法。
self.check_point = flow.train.CheckPoint()if self.pretrain_models != '': self.check_point.load(self.pretrain_models)else: self.check_point.init()self.check_point.save(save_path)
调用 save 函数会保存所有 variable 参数的值到指定目录,每个变量会单独保存到一个子目录。
遇到的一些问题以及解决方法
如何实现 C 次迭代之后再拷贝一次训练网络的参数到预测网络
因为OneFlow 目前并没有可以在作业运行时直接操作参数的方法,所以需要另外定义一个拷贝参数的作业来实现这个功能:
https://github.com/Ldpe2G/DeepLearningForFun/blob/master/Oneflow-Python/DRL-FlappyBird/BrainDQNOneFlow.py#L190
@flow.global_function("predict", get_predict_config())def copyQNetToQnetT(): with flow.scope.placement(DEVICE_TAG, "0:0-%d" % (DEVICE_NUM - 1)): t_conv1_weight, t_conv1_bias, t_conv2_weight, t_conv2_bias, t_fc1_weight, t_fc1_bias, t_fc2_weight, t_fc2_bias = \ getQNetParams(var_name_prefix = "QNet", is_train = True) p_conv1_weight, p_conv1_bias, p_conv2_weight, p_conv2_bias, p_fc1_weight, p_fc1_bias, p_fc2_weight, p_fc2_bias = \ getQNetParams(var_name_prefix = "QNetT", is_train = False) # 用 assign 算子实现参数的拷贝 flow.assign(p_conv1_weight, t_conv1_weight) flow.assign(p_conv1_bias, t_conv1_bias) flow.assign(p_conv2_weight, t_conv2_weight) flow.assign(p_conv2_bias, t_conv2_bias) flow.assign(p_fc1_weight, t_fc1_weight) flow.assign(p_fc1_bias, t_fc1_bias) flow.assign(p_fc2_weight, t_fc2_weight) flow.assign(p_fc2_bias, t_fc2_bias)
然后每C轮迭代调用一次整个作业就实现参数拷贝的功能了:
if localTimeStep % UPDATE_TIME == 0: self.copyQNetToQnetT()
GPU利用率较低
因为整个算法流程涉及到与游戏环境的交互而且网络较小,导致 GPU 整体的利用率不超50%。
目前整个算法大致运行流程如下,首先从环境获取初始状态,然后开始迭代:
把当前状态输入预测网络获取 action;
执行 action,获取新状态和 reward;
把(旧状态, action, reward, 新状态)元组加入 replayMemory ,然后调用 trainQNetwork 函数;
这上面每一步都是同步顺序执行的,不过仔细分析一下会发现,只有预测网络需要与游戏环境做交互。
而训练网络只需要专心更新参数,然后一定迭代次数之后才把参数拷贝给预测网络。
所以对训练函数的调用完全可以放到另外一个线程去执行,而只需要保证对于预测网络的操作和 replayMemory 的操作用 mutex 同步就好了。
这样子简单改进之后,可以让 GPU 的利用率提升 10% 左右。
END


本文版权归 作者梁德澎 所有,如需转载请在文后留言,经允许后方可转载。转载请在文首注明来源、作者及编辑,文末附上 OneFlow 二维码。
扫描文末二维码,加入讨论群,及时获取更多资讯!
点击“阅读原文”,即刻进入 GitHub 仓库!
往期精彩:
时刻为自己加满能量,OneFlow用1300天打造AI框架开源“国产”方案
TensorFlow、PyTorch之后,“国产”AI框架还有没有机会?
30名工程师,历时1300天打造,又一“国产”AI框架开源了
一流科技荣获第五届清华校友创意创新创业大赛(西北赛区)决赛一等奖

如无法入群,可求助 OneFlow 小助手
QQ:3119703778
VX:OneFlowXZS

点击“阅读原文”,即刻进入 GitHub 仓库!
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,我们会坚持分享学习到的知识。
有对文章相关的问题,或者想要加入交流群,欢迎添加本人微信:

二维码
留言区
本文分享自微信公众号 - GiantPandaCV(BBuf233)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。










