
作者: SilverFruity, https://github.com/SilverFruity
小编寄语:
上一周我们发布了《OCRunner 第零篇:从零教你写一个 iOS 热修复框架》。很多读者对这个方案是否能上架特别感兴趣。在这里统一做一下回复:
根据作者描述,这个框架没有调用任何私有 API,目前是可以上架的。
当然,我们也觉得做技术的要对一些新鲜事物带有一棵好奇之心,搞清楚其中原理比这个东西是否能上线比更重要。
至于怎么上线以及是否符合苹果规范就看各家产品决策了。审核本身是一个博弈的过程,毕竟像 RN、Weex 这类的都是可以动态下发代码的,现在有很多产品可以上线。但是像 JSPatch 却又被定义成有安全风险不让上线。
相信看完今天这篇文章的朋友,应该能理解为什么这个方案可以上线。尤其是误以为 OCRunner 是基于 JSCore 一定要花时间好好了解一下哦。
在正文开始前,我们先看看给出的语法树解释执行.gif,OCRunner的核心解释执行部分也是如此。
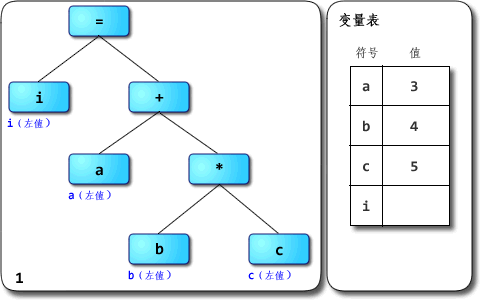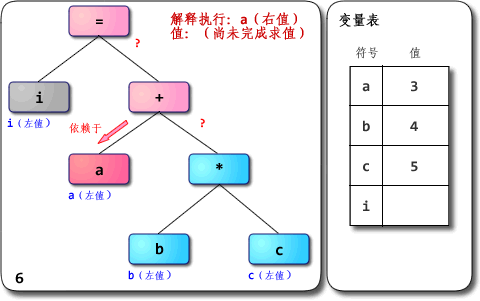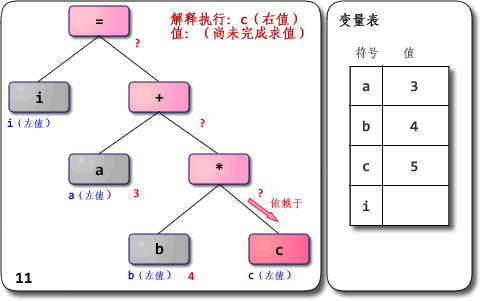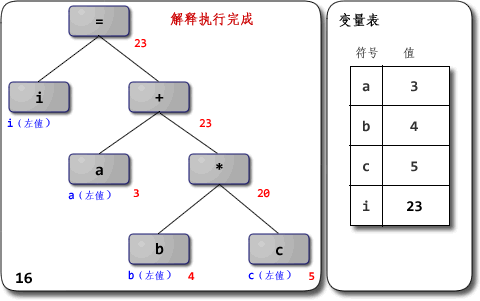
本图出自: 虚拟机随谈(一):解释器,树遍历解释器,基于栈与基于寄存器,大杂烩
如果你让我仅仅只靠文字就能给你解释清楚 OCRunner 是怎么运行起来的,你们可能是在为难我小蒋,肚子里墨水真的没那么多啊,太难了😂。所以在这一小节,我给大家准备了一个简单版 OCRunner,希望大家能从这个例子中,真正知道它是如何运行的。
希望你们看见项目中的 SingleEngine 类不要笑(哈哈哈),我只是想表达 单缸发动机 的意思 - _ -,我心爱的小摩托就是单缸拖拉机。
本节假设读者并不具备编译相关的知识。
本文对 lex 和 yacc 介绍有限,关于 flex 和 bison 的详细使用可以参照《flex与bison中文版》或者 《flex&bison》。
SimpleOCRunnerDemo[1],建议使用 git clone 的形式下载源码,每个小节的相应源码都对应在各自的 commit 里。通过边看文章边阅读源码的形式食用,更香哟。
我们将通过以下这个例子,来说明 OCRunner 执行的主要实现,将省略补丁文件的序列化和加载过程。
现在,我们的目标是让这段文本像 C 一样执行,并且最终变量 c 的值为 5 。
int d = 2; int add(int arg0, double arg1){ return arg0 + arg1 + d; } int a = 1; double b = 2.0; int c = add(a, b);
词法分析器
通俗来说,词法分析就是将符合相应规则的字符串转换为一个 Token(可以将它看为一个由类型和值两个属性组成的类)。
比如当匹配到 'int' 时,'int' 将会被转换为 INT_TYPE ,也是就是 Token 的类型,它的值可以是我们后续的值类型(一个枚举)。
再比如当匹配到 '1.0' 字符串时,'1.0' 被转换为 DOUBLE_LITERAL 类型并且 Token 此时的值为浮点数 1.0。
针对这里例子,我们现在有如下几个规则:
关键词: int、double、return
标识符(可以是变量名、类型等): 以字母、_ 、$ 开头的字符串
数值: 整数、浮点数
符号: ( ) ; { } , = +
上述都是我们接下来需要识别的,我们将直接使用 flex 完成词法分析器。
词法分析器 lexer.l 中的代码:
%option noyywrap %{ #import <Foundation/Foundation.h> #include "y.tab.h" %} %% "," { return ',';} ";" { return ';'; } "(" { return '('; } ")" { return ')'; } "{" { return '{'; } "}" { return '}'; } "=" { return '='; } "+" { return '+'; } "-" { return '-'; } "int" { return INT_TYPE; } "double" { return DOUBLE_TYPE; } "return" { return RETURN; } // 浮点数 [0-9]+\.[0-9]+ { yylval.doubleValue = atof(yytext); return DOUBLE_LITERAL; } // 整数 [1-9][0-9]* { yylval.intValue = (int)strtol(yytext, NULL, 10); return INTETER_LITERAL; } // 标识符 [A-Za-z_$][A-Za-z_$0-9]* { yylval.stringValue = yytext; return IDENTIFIER; } %%
Flex语法简单简介
上半部分的
%{ %}主要用于书写 C 代码,引入头文件,自定义函数等等,最终会以文本的形式被添加到 lexer.yy.c 中( Demo 中你可以在编译缓存中找到该文件)。下半部分的
%% %%就是关键了,通过使用正则表达式,将符合规则的字符流转换为相应的 token 。yylval这则是 Token 的值,默认情况下它一个 int 类型,但是在 bison 中可以使用 %union 声明来重新定义它的类型。
当我们调用词法分析器后,上述文本将会做出如下转换,如何对它进行语法匹配,这就是接下来的内容了。
`int d = 2 ;
INT_TYPE IDENTIFIER = INTETER_LITERAL ;
int add ( int arg0 , double arg1 ) {
INT_TYPE IDENTIFIER ( INT_TYPE IDENTIFIER , DOUBLE_TYPE IDENTIFIER ) {
return arg0 + arg1 + d ;
RETURN IDENTIFIER + IDENTIFIER + IDENTIFIER ;
}
}
int a = 1 ;
INT_TYPE IDENTIFIER = INTETER_LITERAL ;
double b = 2.0 ;
DOUBLE_TYPE IDENTIFIER = INTETER_LITERAL ;
int c = add ( a , b ) ;
INT_TYPE IDENTIFIER = IDENTIFIER ( IDENTIFIER , IDENTIFIER ) ;`
语法分析器
语法分析器 parser.y 中的代码,目前还没有任何语法相关的逻辑。
`%{
#import <Foundation/Foundation.h>
#define YYDEBUG 1
#define YYERROR_VERBOSE
extern int yylex (void);
extern void yyerror(const char *s);
%}
%union{
uint64_t intValue;
double doubleValue;
char *stringValue;
__unsafe_unretained id object;
}
%token
%token
%token
%token INT_TYPE
%token DOUBLE_TYPE
%token RETURN
%start door
%type
%%
door:
/empty/
| statements;
;
statements:
/empty/
;
%%
void yyerror(const char *s){
}
`
Yacc语法简单介绍
%{%}中和 Flex 是一样的。但是关于这里的 yylex 和 yyerror 两个函数,他们两兄弟是必须引入的%union 如之前所说,将重新定义 yylval 的类型,可以在词法分析阶段,保留不同类型的值
%token
IDENTIFIER 将在 yacc 声明一个名为 IDENTIFIER 的 token,并且表明了它的值类型(获取它的值时,将从 union 的哪个字段取值)。%type 与 %token 不同是的,这是声明一条规约(语法规则)。
%start 将从指定的规约,作为语法解析器的入口
关于
%{%}和%% %%,与 flex 不同是的,%% %%中采用 BNF 文法的变种来描述语法规则,当你明白了它的运作方式,其实可读性还是很高的。现在我们需要使用 lexer.l 以及 parser.y ,完成对
a = 1 + 2; b = 2.0 - 1.0;的识别,并且打印计算结果。使用 Yacc 实现对两个表达式的识别以及计算的源码,已经在仓库 SimpleOCRunnerDemo[2] 的 不同类型简单计算的例子[3] 中完成,对 Yacc 语法不熟悉的小伙伴,可以看完这一小部分,再去看源码。为限制本文篇幅,我将尽量减少在文中的代码。
首先我们先将
a = 1 + 2; b = 2.0 - 1.0;转换为 Token ://表达式 1 IDENTIFIER = INTETER_LITERAL + INTETER_LITERAL ; //表达式 2 IDENTIFIER = DOUBLE_LITERAL - DOUBLE_LITERAL ;通俗来说,如果我们逐个逐个的读入每个 Token,我们要匹配上述两个表达式,可以有以下代码逻辑:
extern Token nextToken(void); while(token = nextToken()): if token == IDENTIFIER: if nextToken() == '=': token = nextToken(); if token == INTETER_LITERAL: if nextToken() == '+': if nextToken() == INTETER_LITERAL: //完成 IDENTIFIER = INTETER_LITERAL + INTETER_LITERAL ; return if token == DOUBLE_LITERAL: if nextToken() == '-': if nextToken() == DOUBLE_LITERAL: //完成 IDENTIFIER = DOUBLE_LITERAL - DOUBLE_LITERAL ; return break; // 这个逻辑使用 Yacc 代码可以表示为 assign_expression: IDENTIFIER '=' expression ; expression: INTETER_LITERAL + INTETER_LITERAL | DOUBLE_LITERAL - DOUBLE_LITERAL ; // NAME: 其实是实现了一条规约(语法规则),始终对下一个Token进行匹配,其实中的 | 表示一个 or 的逻辑分支,还有就是规约可以递归使用。更多的Yacc语法可以参阅《flex与bison中文版》53页。
现在让我们回到初始目标,现在我们要实现它相应的语法分析器:
int d = 2; int add(int arg0, double arg1){ return arg0 + arg1 + d; } int a = 1; double b = 2.0; int c = add(a, b);
还记得我们在词法分析器中的实现吗,文本到 Token 的转换规则:
int -> INT_TYPE double -> DOUBLE_TYPE 'a-zA-z' -> IDENTIFIER 1 -> INTEGER_LITERAL 2.0 -> DOUBLE_LITERAL (){}+,=; -> (){}+,=; //字符
首先,我们完全可以确定的是,出现最多的 Token 组合为:
// int/double xxx TYPE IDENTIFIER
同时我们的数据类型有两种,分别为 int / double ,因此我们的第一条规约为:
specifier_type: INT_TYPE |DOUBLE_TYPE ;
接下来,我们来梳理一下所有的声明语法(变量、函数):
int a double b = 2.0 int add(int arg0, int arg1)
针对以上三个声明语法,可以使用以下两个规约匹配:
`// 对int/double xxx统一处理,其他的单独处理即可
declaration:
specifier_type IDENTIFIER
| declaration '=' expression
| declaration '(' declaration_list ')'
;
// declaration_list 就是一个以','为分隔符的列表处理
declaration_list:
declaration
| declaration_list ',' declaration
;
`
接下来我们需要处理表达式,我们这里对表达式简单的定义为:'=' 和 'return' 右部分,不包含 ';' 。
1 1.0 a a + b add(a, b)
针对以上表达式,可以使用的最简规约
`// 处理 1、1.0、a
primary_expression:
IDENTIFIER
| INTETER_LITERAL
| DOUBLE_LITERAL
;
// 处理 a + b、add(a, b)
expression:
primary_expression
| expression '+' expression
| expression '(' expression_list ')'
;
// expression_list与declaration_list雷同
`
实现了expression规约后,实现 return 就很简单了 RETURN expression。
我们将 { ... } 这个整体统称为一个块或者是作用域,它由表达式的列表或者子作用域组成。
在完成对块的匹配之前,我们首先要能够匹配多个不同的声明。
根据已经实现的规约,在其尾部加一个;,完成一个声明的匹配。
因此实现了 statement 规约,用以将各个声明的规约整合。
statement: declaration ';' | expression ';' | RETURN expression ';' ;
其次,我们还需要匹配作用域中的多个声明或者零个声明,那么 statement_list 应运而生。
statement_list: | statement | statement_list statement ;
这个时候,我们已经能够处理作用域中的声明列表了,那么针对作用域的规约如下:
scope_statements: '{' statement_list '}' ;
目前就只有对函数的声明没有实现了,但我们早已在 declaration 中实现了对了 int add(int a, double b) 识别。最终的 statement 规约如下:
statement: declaration ';' | expression ';' | RETURN expression ';' //函数声明的识别 | declaration scope_statements ;
本小节相关代码,在SimpleOCRunnerDemo[4] 的 section 语法分析[5] 提交中。
生成语法树
在我们这个例子中,语法树中需要的节点如下(如果小伙伴想添加更多的语法,可自行更改):
所有节点都继承自ASTNode类。
ASTSpecifierNode变量类型节点:
int,doubleASTDeclareNode变量声明节点:
int aASTValueNode值节点:
2,1.0,aASTInitDeclareNode变量初始化声明节点:
double b = 2.0ASTBinaryNode二元运算节点:
a + bASTScopeNode作用域节点:
{}ASTFunctionDeclareNode函数声明节点:
int add(int arg0, double arg1)ASTFunctionImpNode函数节点:
int add(int arg0, double arg1) { }**ASTReturnNode **return节点:
return xxxASTFunctionCallNode函数调用节点:
add(a, b)
ASTSpecifierNode int/double:我们这里其实就是一个简单枚举,但我们还添加了类型名称的属性
`typedef enum{
ASTSpecifierTypeInt,
ASTSpecifierTypeDouble
}ASTSpecifierType;
@interface ASTSpecifierNode: ASTNode
@property (nonatomic, assign) ASTSpecifierType type;
@property (nonatomic, strong) NSString *typeName;
@end
`
ASTDeclareNode int a: 可以看出由一个变量类型( ASTSpecifierNode )和变量名组成
@interface ASTDeclareNode: ASTNode @property (nonatomic, strong) ASTSpecifierNode *type; @property (nonatomic, strong) NSString *varname; @end
ASTValueNode 2, 1.0, a: 有三种值,整型、浮点数、变量名
在我们的代码中存在两种变量,标识符:a,标量:1.0 ...,同时一个变量只能拥有一个值和一个值类型,所以我们使用enum ASTValueNodeType + union ASTValueNodeValue的形式来完成类型和值的对应。
`typedef enum{
ASTValueNodeIdentifier,
ASTValueNodeInt,
ASTValueNodeDouble
}ASTValueNodeType;
typedef union {
void *pointerValue;
int64_t intValue;
double doubleValue;
}ASTValueNodeValue;
@interface ASTValueNode: ASTNode
@property (nonatomic, assign) ASTValueNodeType type;
@property (nonatomic, assign) ASTValueNodeValue value;
@end
`
ASTInitDeclareNode double b = 2.0: 此时我们再处理初始化声明表达式的数据结构就很简单了,由变量声明节点和值节点组成,结构如下
@interface ASTInitDeclareNode: ASTNode @property (nonatomic, strong) ASTDeclareNode *declare; @property (nonatomic, strong) ASTNode *expression; @end
ASTBinaryNode a + b: 主要有左右两个表达式以及中间的操作符组成
事实上,左右的表达式可能并不单单只是一个变量名(或者表达式),因此,我们这里使用的是ASTNode
`typedef enum {
ASTBinaryNodeOperatorAdd
}ASTBinaryNodeOperator;
@interface ASTBinaryNode: ASTNode
@property (nonatomic, assign) ASTBinaryNodeOperator operator;
@property (nonatomic, strong) ASTNode *left;
@property (nonatomic, strong) ASTNode *right;
@end
`
ASTScopeNode {} 中主要存在的是多个语法节点,因此,其属性只有一个存储节点的数组
ASTFunctionDeclareNode int add(int a, double b),主要由一个 ASTDeclareNode(int add)和它的数组(int a, double b)组成
ASTFunctionImpNode int add(int a, double b) { },则是由上述两个节点组成
ASTFunctionCallNode add(a, b) ,由一个调用者节点和参数节点数组组成
因此他们的结构如下:
`@interface ASTScopeNode : ASTNode
@property (nonatomic, strong) NSMutableArray *nodes;
@end
@interface ASTFunctionDeclareNode: ASTNode
@property (nonatomic, strong) ASTDeclareNode *declare;
@property (nonatomic, strong) NSMutableArray *argDeclares;
@end
@interface ASTFunctionImpNode: ASTNode
@property (nonatomic, strong) ASTFunctionDeclareNode *declare;
@property (nonatomic, strong) ASTScopeNode *scope;
@end
@interface ASTFunctionCallNode: ASTNode
@property (nonatomic, strong) ASTNode *caller;
@property (nonatomic, strong) NSMutableArray *args;
@end
`
最终 parser.y 中的部分代码如下,globalAst 为一个全局的语法树变量:
door: statement_list { globalAst.nodes = $1; } ; statement_list: { __autoreleasing id value = [NSMutableArray array]; $$ = value; } | statement_list statement { [$1 addObject: $2]; $$ = $1; } ; .......
关于在 .l 和 .y中书写代码不方便的问题,可以在 vscode 中安装 flex 和 bsion 的相关插件,有了代码提示,体验会好很多很多。
单元测试
为什么会在这儿提到单元测试呢?
oc2mango 以及 OCRunner 能够开发出来,单元测试有超大功劳。
针对 oc2mango 方面,随着项目的发展,越来越多的语法需要支持,当你在修改语法分析器的时候,稍有一个不慎,就极有可能导致已经支持的语法变成不支持,没有单元测试的话,后续的开发几乎就寸步难行了。现在反思一下,每留下一个爆红的测试示例,有时也像一个一个挑战,等着你去征服他们,绿了以后感觉贼爽。
之前我们一直没有提到单元测试,但在目前这个阶段,我们已经可以愉快的使用单元测试了(其实我们在最开始的时候就应该使用的😂,篇幅有限啊)。
目前我们的单元测试目标很明确:检验生成的语法树是否正确。
那我们的输入->输出的概念应该为:源码->语法树->单元测试->是否正确。
之前的代码,我们是无法通过 [SingleEngine run:] 得到语法树的,因此我们在SingleEngine中添加了一个 + (AST *)parse: (NSString *)source的类方法,用于完成:源码->语法树。
为了方便单元测试,也在 SingleEngine 中特意添加了一个 parserError 用于最基础的语法测试判断。
当你打算尝试加入一个新的语法时,你可以写一个最简单的关于 parserError 的单元测试,亮一个红灯。
示例:SimpleOCRunnerDemoTests.m 中的 testExample 代码:
`- (void)testExample {
NSString *source =
@"int a = 1;"
"double b = 1.0;";
AST *ast = [SingleEngine parse:source];
XCTAssert(parserError == nil, @"error: %@", parserError);
ASTInitDeclareNode *node1 = (ASTInitDeclareNode *)ast.nodes.firstObject;
XCTAssert([node1 isKindOfClass:[ASTInitDeclareNode class]]);
XCTAssert([node1.declare.varname isEqual:@"a"]);
XCTAssert(node1.declare.type != nil);
XCTAssert(node1.declare.type.type == ASTSpecifierTypeInt);
XCTAssert([node1.expression isKindOfClass:[ASTValueNode class]]);
XCTAssert([(ASTValueNode *)node1.expression value].intValue == 1);
ASTInitDeclareNode *node2 = (ASTInitDeclareNode *)ast.nodes.lastObject;
XCTAssert([node2 isKindOfClass:[ASTInitDeclareNode class]]);
XCTAssert([node2.declare.varname isEqual:@"b"]);
XCTAssert(node2.declare.type != nil);
XCTAssert(node2.declare.type.type == ASTSpecifierTypeDouble);
XCTAssert([node2.expression isKindOfClass:[ASTValueNode class]]);
XCTAssert([(ASTValueNode *)node2.expression value].doubleValue == 1.0);
}
`
本小节相关代码位于 Section: 生成语法树[6].
执行语法树
int d = 2; int add(int arg0, double arg1){ return arg0 + arg1 + d; } int a = 1; double b = 2.0; int c = add(a, b);
在开始正文以前,我们先思考几个问题:
int a = 1;,关于 a 的值,应如何存储,并且在后续的计算中还能获取到 a 的值?int a = 1; double b = 1.0; int c = a + b;,关于这里,在计算 c 时,a 和 b 的值,如何才能获取到,并且 a、b 的值是两个不同的类型,如何让他们以自己的类型进行计算,并且最终的值被强转为int?add(a , b);函数调用时,参数如何传递?在
add函数的调用中, d 的值如何获取?如何兼容的 Objective-C 的 TypeEncode [7]?
现在有几个概念需要讲一下了。
作用域(EvalScope)
{ }就可视为一个作用域,EvalScope 主要由一个 NSMuatbleDictionary 和一个父作用域的引用组成。
它的作用主要是:
1.存储在当前作用域中声明的变量的值,比如: int a = 1,EvalScope["a"] = ORValue(1)。当 int b = a 这种情况时,则会去 EvalScope 查找 'a' 变量的值,然后再注册一个 'b' 的变量。
2.父作用域的引用主要用于跨域操作时,跨域变量查找以及修改。我们的例子中,也出现了这种情况。
中间值(ORValue)
站在作用域的基础之上,在字典中保存的值,需要是一个对象。
尽管目前我们只需要处理 int 和 double 类型的值,但随着类型的增加,需要一个类来封装类型处理的相关逻辑以及值在内存中的存储的。
为了兼容 Objective-C 的 TypeEncode,在类中,添加一个 typeEncode 的属性,以做到:ORValue = 值 + TypeEncode 的组合。
同时,为了能够控制当前的执行状态,拥有一个 controlState 属性,用于在代码中实现 return 、continue、break。
全局函数表(FunctionTable)
为了全局函数能够正常调用,比如通过 add(1, 0) 的形式,即可调用add函数的实现。因此我们实现了一个单例主要用于存储 [String : ASTFunctionImpNode] 的字典。
关于 ASTFunctionImpNode 的注册和执行的问题:
当遍历 execute 语法树时,此时为第一次调用 ASTFunctionImpNode.execute ,这个时候会向全局函数表进行注册,此时 EvalArgsStack 中的元素的个数必定为0。所有的函数和方法调用的时候,此时 EvalArgsStack 的元素的个数必定 >= 1,因此除了第一次注册执行以外,此后 ASTFunctionImpNode 所有的 execute,都进行解释执行操作。
函数参数栈(EvalArgsStack)
它其实很简单。在函数调用前,先将所有的参数按照顺序组成一个数组压入栈中,函数执行时,从栈顶取出数组,随后注册到函数作用域中,当函数执行完成后,再将参数数组出栈。
当函数执行时,是如何获取到他们的值的呢?
//我们再回顾一下 函数声明的结构 @interface ASTFunctionDeclareNode: ASTNode @property (nonatomic, strong) ASTDeclareNode *declare; @property (nonatomic, strong) NSMutableArray <ASTDeclareNode *>*argDeclares; @end
已知 int add(int arg0, double arg1){ } 我们调用add(1, 0);。
首先,我们使用 'add' 在 FunctionTable 中查找到 add 函数的实现(ASTFunctionImpNode)。
调用函数实现前,先执行[EvalArgsStack.push:@[ORValue(1), ORValue(0)]]。
最终 ASTFunctionImpNode.exexcute 时,向作用域中注册参数变量的逻辑如下:
NSArray *args = [EvalArgsStack top]; NSArray *declares = self.declare.argDeclares; functionSubScope[declares[0].varname] = args[0]; //functionSubScope["arg0"] = args[0]; functionSubScope[declares[1].varname] = args[1]; //functionSubScope["arg1"] = args[1];
关于最终代码运行的逻辑如下:
int d = 2; // TopScope[“d”] = ORValue(2); int add(int arg0, double arg1){ // ASTFunctionImpNode.exexcute(SubScope) -> ORValue: // list<ORValue> = ArgsStack.last // SubScope[“arg0”] = list[0] = ORValue(1) // SubScope[“arg1”] = lsit[1] = ORValue(2.0) // d = SubScope->superScope[“d”] = TopScope[“d”] = ORValue(2) // return ORValue(1) + ORValue(2.0) + ORValue(2) return arg0 + arg1 + d; } int a = 1; // TopScope[“a”] = ORValue(1); double b = 2.0; // TopScope[“b”] = ORValue(2.0); int c = add(a, b); // ASTFunctionImpNode = GlobalFunctionTable[“add”] // ArgsStack.push([a, b]) // SubScope->superScope = TopScope // TopScope[“c”] = ASTFunctionImpNode.exexcute(SubScope) // ArgsStack.pop()
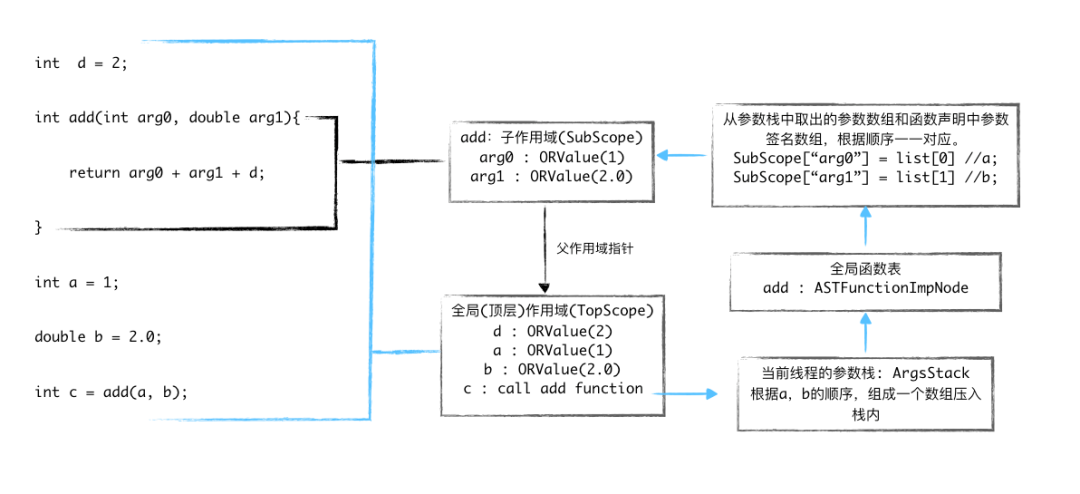
整体运行
本小节相关代码位于Section: 执行语法树[8].
在这个简单的 demo 里面,许多功能都还未完成:操作符、基本类型转换、指针、方法替换、控制语句、结构体等等,但我希望能够让小伙伴们对语法树解释执行有一个基本的了解。针对未实现的功能,想深入的人,完全可以通过修改 demo,完成以上功能,疑惑的地方,可以查看 OCRunner 的源码。
One More Thing
这是一个系列文章,感兴趣的可以关注一下「老司机技术周报」公众号,后续文章都会在公众号中发布。感兴趣的也可以看一下之前已经发布的文章:
OCRunner 第零篇:从零教你写一个 iOS 热修复框架
关注我们
我们是「老司机技术周报」,每周会发布一份关于 iOS 的周报,也会定期分享一些和 iOS 相关的技术。欢迎关注。

关注有礼,关注【老司机技术周报】,回复「2020」,领取学习大礼包。
后续规划
OCRunner 第二篇:二进制补丁文件的实现
以上,作者正在快马加鞭打磨中.....
参考资料
[1]
SimpleOCRunnerDemo: https://github.com/SilverFruity/SimpleOCRunnerDemo
[2]
SimpleOCRunnerDemo: https://github.com/SilverFruity/SimpleOCRunnerDemo
[3]
不同类型简单计算的例子: https://github.com/SilverFruity/SimpleOCRunnerDemo/commit/c09d35868207ec44e7a4854552e9b19246f561d1
[4]
SimpleOCRunnerDemo: https://github.com/SilverFruity/SimpleOCRunnerDemo
[5]
section 语法分析: https://github.com/SilverFruity/SimpleOCRunnerDemo/commit/850de3fe2db9ce3a059e809560bb2fb88ea3ac06
[6]
Section: 生成语法树: https://github.com/SilverFruity/SimpleOCRunnerDemo/commit/4f27bd65488a2cf9b669b1047ab242b2f8a5999d
[7]
[8]
Section: 执行语法树: https://github.com/SilverFruity/SimpleOCRunnerDemo/commit/33e2358c4e06baa1f35d4309b76f376a753f58fc
本文分享自微信公众号 - 老司机技术周报(LSJCoding)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











