推荐
专栏
教程
课程
飞鹅
本次共找到108条
反斜杠
相关的信息
菜鸟阿都
•
4年前
创建免费ip代理池
     反爬技术越来越成熟,为了爬取目标数据,必须对爬虫的请求进行伪装,骗过目标系统,目标系统通过判断请求的访问频次或请求参数将疑似爬虫的ip进行封禁,要求进行安全验证,通过python的第三方库faker可以随机生成header伪装请求头,并且减缓爬虫的爬取速度,能很好的避过多数目标系统的反扒机制,但对一些安全等级
Wesley13
•
4年前
java爬虫进阶 —— ip池使用,iframe嵌套,异步访问破解
写之前稍微说一下我对爬与反爬关系的理解一、什么是爬虫 爬虫英文是splider,也就是蜘蛛的意思,web网络爬虫系统的功能是下载网页数据,进行所需数据的采集。主体也就是根据开始的超链接,下载解析目标页面,这时有两件事,一是把相关超链接继续往容器内添加,二是解析页面目标数据,不断循环,直到没有url解析为止。举个栗子:我现在要爬取苏宁手机价
helloworld_78018081
•
4年前
2021年春招Android面试题,详细解说
来,发车了!1.战略定位:Android面试都会问些什么?要打败敌人首先需要摸清敌人。Android面试有它固有的套路。一般大厂的面试包括技术面3HR面1。技术面中一面考察基础知识,这一面相对容易,只要你把我下面给出的武林秘籍背熟就易如反掌。这一面大约占40%;二面侧重项目经历/应对问题能力,这一面要求普遍较高,需要学会应用知识,更注重于优
爱丽丝13
•
4年前
新手学习 React 迷惑的点
网上各种言论说React上手比Vue难,可能难就难不能深刻理解JSX,或者对ES6的一些特性理解得不够深刻,导致觉得有些点难以理解,然后说React比较难上手,还反人类啥的,所以我打算写两篇文章来讲新手学习React的时候容易迷惑的点写出来,如果你还以其他的对于学习React很迷惑的点,可以在留言区里给我留言。为什么要引入Reac
Karen110
•
4年前
盘点那些年我们一起玩过的网络安全工具
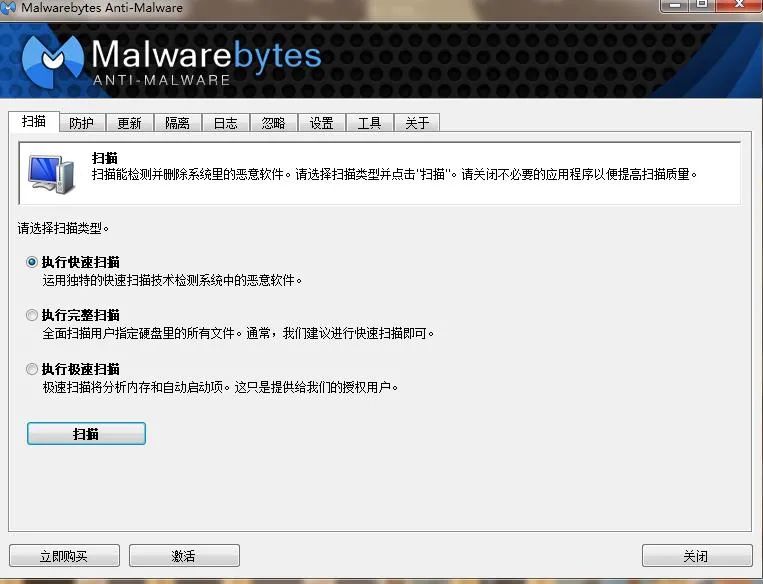
大家好,我是IT共享者,人称皮皮。这篇文章,皮皮给大家盘点那些年,我们一起玩过的网络安全工具。一、反恶意代码软件1.Malwarebytes这是一个检测和删除恶意的软件,包括蠕虫,木马,后门,流氓,拨号器,间谍软件等等。快如闪电的扫描速度,具有隔离功能,并让您方便的恢复。包含额外的实用工具,以帮助手动删除恶意软件。分为两个版本,Pro和Free,Pro
李志宽
•
3年前
重拳出击!我是这样对灰产外挂下手的
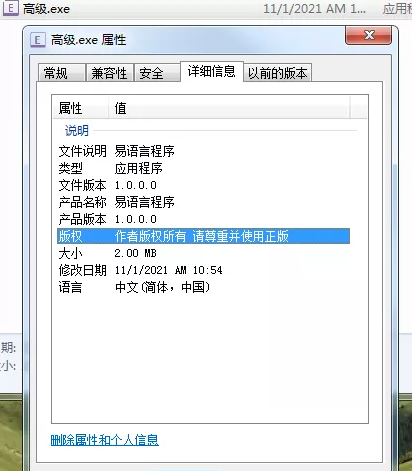
分析外挂样本一般的步骤1.对外挂样本进行简单的信息分析。2.分析还原外挂样本具体功能实现方式。3.分析外挂样本的反检测功能。1.对外挂样本进行简单的信息分析查看文件属性,灰产及外挂的标配语言“易语言”通过ExeinfoPe查壳工具进行对外挂样本查壳,看看发现是没加壳的应用程序。(心里突然咯噔了下,收费的外挂竟然都不做点保护,不对自己的程序负
Python进阶者
•
4年前
盘点那些年我们一起玩过的网络安全工具
大家好,我是IT共享者,人称皮皮。这篇文章,皮皮给大家盘点那些年,我们一起玩过的网络安全工具。一、反恶意代码软件1.Malwarebytes这是一个检测和删除恶意的软件,包括蠕虫,木马,后门,流氓,拨号器,间谍软件等等。快如闪电的扫描速度,具有隔离功能,并让您方便的恢复。包含额外的实用工具,以帮助手动删除恶意软件。分为两个版本,Pro和Free,Pro版
Wesley13
•
4年前
IP库购买需要注意哪些事项?
众所周知IP地址数据库在众多领域具有重要意义。互联网安全行业攻防定位方面,通过定位IP,确定网络攻击IP的来源,进行网络安全防御。如政府部门,通过定位网络攻击IP的地理位置,确定网络攻击的发起位置。互联网金融行业风险控制方面,互联网金融征信、反欺诈和位置核验。如保险公司,通过确定客户IP的位置,确定客户是否出现在常住地,从而降低信贷风险。互联网
京东云开发者
•
2年前
一种配置化的数据脱敏与反脱敏框架实现 | 京东云技术团队
在现有的微服务技术架构背景下,敏感数据的使用存在许多痛点,基于此,tony提供了一套完整、安全、透明化、低改造成本的数据脱敏整合解决方案。
小万哥
•
1年前
NumPy 差分、最小公倍数、最大公约数、三角函数详解
NumPy助你处理数学问题:计算序列的差分用np.diff(),示例返回5,10,20;找最小公倍数(LCM)用np.lcm(),数组示例返回18;最大公约数(GCD)用np.gcd.reduce(),数组示例返回4;三角函数如np.sin(),np.deg2rad()用于角度弧度转换。别忘了np.arcsin()等反三角函数,以及np.hypot()求斜边长度。学习NumPy,科学计算更轻松!
1
•••
9
10
11