推荐
专栏
教程
课程
飞鹅
本次共找到2932条
python爬虫
相关的信息
Python进阶者
•
3年前
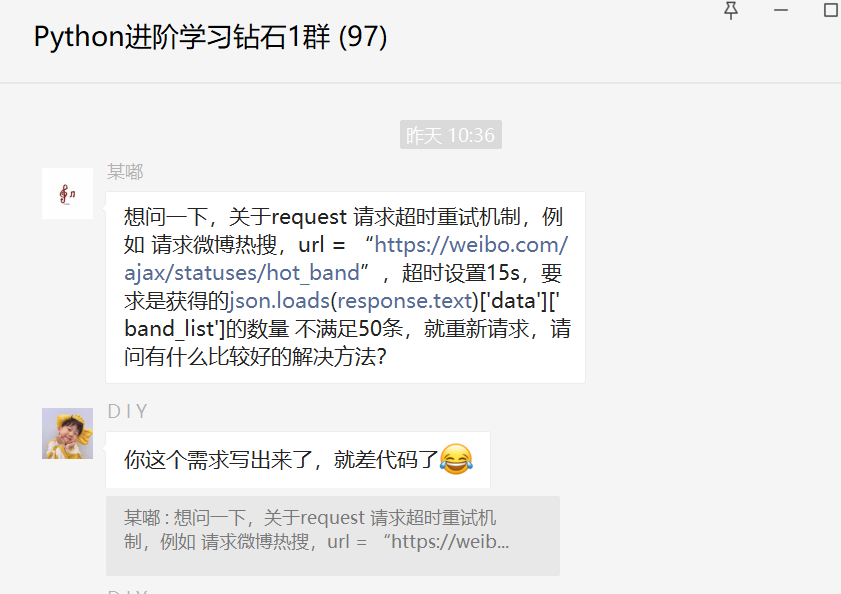
Python网络爬虫中重新请求,请问有什么比较好的解决方法?
大家好,我是皮皮。一、前言前几天在Python钻石群有个叫【某嘟】的粉丝问了一个关于Python网络爬虫中重新请求的问题,这里拿出来给大家分享下,一起学习。二、解决过程这里【DIY】大佬给了一个思路,确实可行。不过后来她自己又找到了一个更好的方法,找到一个HTTPAdapter可以实现超时重试,大概用法如下:fromrequests.adapter
Irene181
•
4年前
详解4种类型的爬虫技术
导读:网络爬虫是一种很好的自动采集数据的通用手段。本文将会对爬虫的类型进行介绍。作者:赵国生王健来源:大数据DT(ID:hzdashuju)聚焦网络爬虫是“面向特定主题需求”的一种爬虫程序,而通用网络爬虫则是捜索引擎抓取系统(Baidu、Google、Yahoo等)的重要组成部分,主要目的是将互联网上的网页下载到本地,形成一个互联网内
Irene181
•
4年前
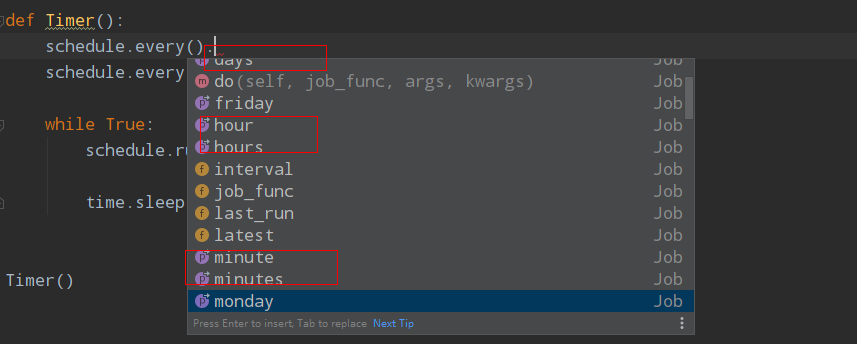
Python爬虫定时计划任务的几种常见方法
记得以前的Windows任务定时是可以正常使用的,今天试了下,发现不能正常使用了,任务计划总是挂起。接下来记录下Python爬虫定时任务的几种解决方法。1方法一、while True首先最容易的是whiletrue死循环挂起,不废话,直接上代码:import osimport timeimport sys from dateti
把帆帆喂饱
•
4年前
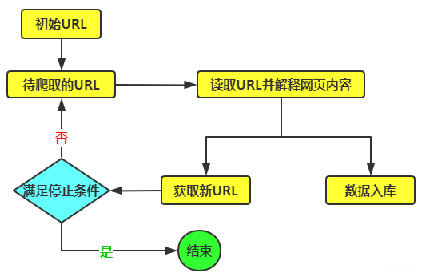
爬虫
爬虫什么是爬虫使用编程语言所编写的一个用于爬取web或app数据的应用程序怎么爬取数据1.找到要爬取的目标网站、发起请求2.分析URL是如何变化的和提取有用的URL3.提取有用的数据爬虫数据能随便爬取吗?遵守robots.txt协议爬虫的分类通用网络爬虫百度,Google等搜索引擎,从一些初识的URL扩展到整个网站,主要为门户站点搜索引擎和大型网站服务采
Stella981
•
4年前
Scrapy爬虫框架下执行爬虫的方法
在使用Scrapy框架进行爬虫时,执行爬虫文件的方法是scrapycrawlxxx,其中xxx是爬虫文件名。 但是,当我们在建立了多个文件时,使用上面的命令时会比较繁琐麻烦,我们就可以使用下述方法同时完成爬虫文件的执行。 第一种,在scrapy框架下建立一个运行文件,如run.py,在文件中建立一个列表,列表为爬虫的执行命令,
Python进阶者
•
2年前
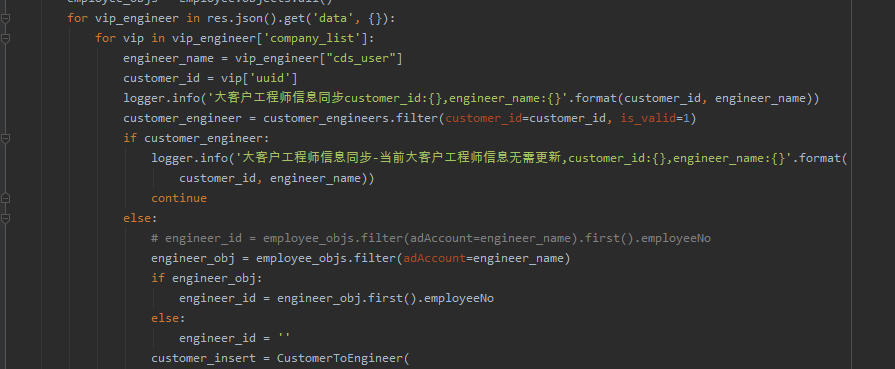
盘点一个ddddocr实现登录的实战案例
大家好,我是皮皮。一、前言前几天在Python白银交流群【空翼】问了一个Pyhton网络爬虫的问题,这里拿出来给大家分享下。二、实现过程一开始看上去并不能登录,找不到原因在哪,后来【甯同学】帮忙搞定了,代码如下:coding:utf8@Author:Kon
小白学大数据
•
8个月前
如何通过requests和time模块限制爬虫请求速率?
一、为什么需要限制爬虫请求速率?在爬取网站数据时,网站服务器需要处理我们的请求并返回数据。如果爬虫的请求过于频繁,服务器可能会因为负载过高而崩溃,或者将我们的爬虫IP地址封禁。此外,许多网站都有反爬虫机制,例如检测单位时间内来自同一IP的请求频率。如果请求
linbojue
•
4个月前
用C语言提升网络爬虫效率的策略指南
011.网络爬虫简介网络爬虫是一种能够自动获取和解析网页内容的工具,利用C语言编写网络爬虫程序能够有效地提取所需数据。通过C语言,您可以轻松地实现对网页的解析和数据的提取。1.1◆C语言与网络爬虫在C语言中,您可以利用诸如cspider这样的库来简化网络爬
1
•••
15
16
17
•••
294